Категории водительских прав: расшифровка 2019 года
Водительское удостоверение категории А
Итак, категория А – это разрешение управлять любыми мотоциклами, включая оснащенными боковым прицепом (коляской). Согласно Правилам дорожного движения, категория А также разрешает управлять трех- и четырехколесными транспортными средствами снаряженной массой не более 400 кг.
Подкатегория А1 – условно «младшая», допускающая езду на мотоциклах с объемом двигателя не более 125 куб. см и мощностью, не превышающей 11 кВт. Кстати, подкатегорию А1 разрешается открывать в 16 лет и, разумеется, те, у кого в водительском удостоверении открыта категория «А», могут управлять техникой подкатегории А1.
Водительское удостоверение категории B
Самая распространенная категория B. Согласно определению ПДД это «автомобили (за исключением транспортных средств категории «А»), разрешенная максимальная масса которых не превышает 3500 килограммов и число сидячих мест которых, помимо сиденья водителя, не превышает восьми; автомобили категории В, сцепленные с прицепом, разрешенная максимальная масса которого не превышает 750 килограммов; автомобили категории В, сцепленные с прицепом, разрешенная максимальная масса которого превышает 750 килограммов, но не превышает массы автомобиля без нагрузки, при условии, что общая разрешенная максимальная масса такого состава транспортных средств не превышает 3500 килограммов». То есть, сюда относятся легковушки, легкие грузовики и микроавтобусы, а также мотоколяски и автомобили с прицепом, разрешенная максимальная масса которого не более 750 кг. Главное, чтобы разрешенная максимальная масса прицепа не превышала массу машины без нагрузки, а их суммарная масса не выходила за пределы 3,5 тонн.
То есть, сюда относятся легковушки, легкие грузовики и микроавтобусы, а также мотоколяски и автомобили с прицепом, разрешенная максимальная масса которого не более 750 кг. Главное, чтобы разрешенная максимальная масса прицепа не превышала массу машины без нагрузки, а их суммарная масса не выходила за пределы 3,5 тонн.
Водительское удостоверение категории BE
Если есть необходимость таскать за собой тяжелый прицеп массой более 750 кг и превышающей массу автомобиля без нагрузки, то потребуется категория BE. Также она позволяет управлять автомобилями категории В с прицепами, разрешенная максимальная масса которых превышает 750 килограммов, при условии, что общая разрешенная максимальная масса такого состава транспортных средств превышает 3500 килограммов.
Подкатегория B1 открывает доступ к трициклам и квадрициклам.
Водительское удостоверение категории М
Раз уж зашла речь о «квадриках», то следует упомянуть и эту категорию для мопедов и легких квадрициклов. Она же по умолчанию является открытой для тех, у кого открыта любая категория.
Она же по умолчанию является открытой для тех, у кого открыта любая категория.
Водительское удостоверение категории С
Это – та самая «грузовая» категория, дающая право на управление серьезными транспортными средствами: средними (разрешенной максимальной массой от 3500 кг до 7500 кг) и тяжелыми (более 7500 кг) грузовиками, а также грузовиками с прицепом, разрешенная максимальная масса которого не превышает 750 кг. Важный момент — категория C не разрешает ездить на небольших (меньше 3500 кг) грузовиках и легковушках.
Водительское удостоверение категории СE
Категория CE нужна для езды с тяжелым (более 750 кг) прицепом или полуприцепом.
Подкатегория С1 – это средние грузовики, разрешенной максимальной массой от 3 500 до 7 500 кг. Она же допускает езду с легким прицепом массой до 750 кг. Соответственно, при открытой категории С можно управлять машинами подкатегории С1.
Наконец есть подкатегория С1Е, введенная для транспортных средств С1 с тяжелыми прицепами массой более 750 кг, но суммарной разрешенной максимальной массой грузовика и прицепа не более 12 тонн.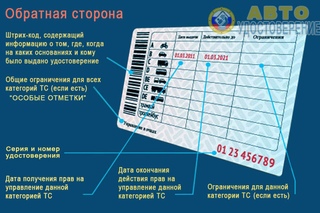 Управлять транспортными средствами подкатегории C1E можно с открытой категорией СЕ.
Управлять транспортными средствами подкатегории C1E можно с открытой категорией СЕ.
Водительское удостоверение категории D
Разрешает управлять автобусами самых разных размеров и без привязки к разрешенной максимальной массе, а также автобусами с прицепом, разрешенной максимальной массой не более 750 кг. Впрочем, есть и исключения – категория D не позволяет ездить на сочлененных автобусах, известных как автобусы с «гармошкой».
Водительское удостоверение категории DE
Это автомобили категории D с прицепом, разрешенная максимальная масса которого превышает 750 килограммов, а также сочлененные автобусы.
Есть и две подкатегории – D1 и D1E. Первая введена для автомобилей, предназначенных для перевозки пассажиров и имеющие более восьми, но не более шестнадцати сидячих мест, помимо сиденья водителя, а также для машин с прицепом, разрешенной максимальной массой до 750 кг. Вторая же — автомобили подкатегории D1 с прицепом, не предназначенные для перевозки пассажиров, разрешенной максимальной массой свыше 750 кг, но не более массы автомобиля без нагрузки, при условии, что общая разрешенная максимальная масса такого состава транспортных средств не превышает 12 000 кг.
Водительское удостоверение категории Tm и Tb
Специфичные категории для трамваев Tm и троллейбусов Tb.
Категории водительских прав в Казахстане в 2019 году
Любому человеку, который решил сесть за руль автомобиля, для начала необходимо изучить теорию и практику вождения. Правительство Казахстана ежегодно упрощает процедура оформления прав.
Сегодня получить права в Казахстане можно за один час в СпецЦОНе, здесь можно пройти все этапы.
В 2019 году в Казахстане отменили обязательное прохождение курсов в автошколах. Сегодня если у человека имеются необходимые навыки, он может сдать экзамен в СпецЦОНе. Если сдача окажется успешной, ему будут выданы водительские права.
Процесс получения прав состоит из ряда этапов:
- Обучение ПДД и вождению;
- Прохождение медкомиссии по форме 083-У;
- Сдача экзаменов;
- Оформление и подача требуемых документов на оформление прав, оплата госпошлины в размере 2 478 тенге.

Содержание статьи
Категории водительских прав
По проекту закона «О дорожном движении» были созданы новые категории прав.
Сегодня в Казахстане действуют следующие водительские категории:
- «A» Требуется для оформления удостоверения на вождение мотороллера, мотоцикла и других мототранспортных средств. Получить ее можно лишь после 16 лет;
- «A1» Она нужна для вождения мотоцикла с рабочим объемом двигателя, который не выше 125 см куб. и имеет мощность 11 кВт;
- «B» Эта категория действует для авто, массой не выше 3,5 тонн и количеством посадочных мест не больше 8, а также для ТС с прицепом, вес которого не превосходит 750 кг;
- «B1» Действует для квадроциклов;
- «C» Действительна для автомобилей, масса которых не выше 3,5 тонн, и авто с прицепом, допустимый вес которого не превышает 750 кг;
- « C1» Действует для ТС, которые не относятся к категории «D» и «D1», массой более 3,5 тонн, но не больше 7,5 тонн, а также ТС категории «C1» с прицепом, весом не больше 750 кг;
- «D» Эта категория предназначается для автомобилистов, осуществляющих транспортировку пассажиров на авто, имеющих более 8 мест, а также для водителей ТС с прицепом, имеющим массу более 750 кг;
- «D1» Нужны для вождения автомобилей, приспособленных для транспортировки людей и имеющих больше 8, но не больше 16 посадочных мест или для управления авто с прицепом, имеющим массу до 750 кг;
- «BE» Она распространяется на авто категории «B», скрепленные с прицепом, вес которого находится в пределах 750 кг и превосходит по массе ТС без нагрузки, а также на ТС категории «B», которые скреплены с прицепом массой до 750 кг и имеют максимальный вес автопоезда более 3,5 тонн;
- «CE» Распространяется на авто категории «C», которые скреплены с прицепом, имеющим массу больше 750 кг;
- «С1Е» Распространяется на авто категории «C1», которые скреплены с прицепом, имеющим массу более 750 кг, но не более массы ТС без нагрузки.
 При этом общий вес состава не должен превосходить 12 тонн;
При этом общий вес состава не должен превосходить 12 тонн; - «DE» Она распространяется на авто категории «D», которые скреплены с прицепом, весящим 750 кг;
- «D1E» Сюда относятся авто категории «D1», которые скреплены с прицепом весом 750 кг, превышающим вес ТС без нагрузки. Общая допустимая масса состава не должна быть выше 12 тонн.
Как оформить водительское удостоверение?
Чтобы получить права, нужно будет прежде всего оформить медсправку по форме 083-У. Пройти медосмотр можно в клинике, имеющей право на выдачу таких справок, а также в СпецЦОНе.
После получения справки понадобится пройти соответствующие экзамены, которые состоят из 2 частей, теоретической и вождения:
- Экзамен по теории проходит в виде теста на компьютерах. Он включает в себя 40 вопросов. Тестирование занимает 40 минут.
 На один вопрос выделяется всего минута. Если теоретический экзамен будет сдан неудачно, будущему водителю будет представлена возможность пересдачи.
На один вопрос выделяется всего минута. Если теоретический экзамен будет сдан неудачно, будущему водителю будет представлена возможность пересдачи. - Если теоретический экзамен будет пройден успешно, претенденту на права придется пройти практический экзамен. Он включает в себя два этапа: выполнение упражнений на автодроме и езду в городских условиях. В последнем случае водителю необходимо будет проехать по заданному маршруту и не совершить серьезных ошибок. Длится такой экзамен как минимум 20 минут. В случае, если экзаменуемый допустил грубые ошибки, экзамен может быть прекращен раньше срока.
Какие документы требуются для получения прав?
Документы следует подавать в СпецЦОНы. Если нет возможности подать документы в СпецЦОН, нужно обратиться в регистрационное полицейское отделение.
Предоставляются следующие документы:
- Оформленным бланком на выдачу прав;
- Документом, удостоверяющим личность;
- Адресной справкой;
- Медсправкой;
- Квитанцией, свидетельствующей об оплате пошлины;
- Экзаменационным листом.

Получить удостоверение международной формы без сдачи экзаменов можно на срок до 3 лет, но не больше того срока, в течение которого действуют национальные права.
Чтобы оформить новые права, следует подать заявку на портале «электронного правительства». Процесс получения удостоверения в этом случае будет очень простым. На портале нужно будет зарегистрироваться или войти в свой личный кабинет. После этого понадобится заполнить все обязательные поля и прикрепить фото и отсканированный образец подписи. После этого нужно будет оплатить услугу с помощью платежной карты и подписать запрос с помощью электронной цифровой подписи.
После отправления данного запроса понадобится посетить СпецЦОН для того, чтобы получить водительские права. При себе нужно будет иметь уведомление, права, документ, удостоверяющий личность и медсправку.
Видео о требованиях получения ВУ в Казахстане
Внимание!
В связи с частыми изменениями законодательства РФ, информация на сайте не всегда успевает обновляться, поэтому для Вас круглосуточно работают бесплатные эксперты-юристы!
Горячие линии:
Москва: +7 (499) 653-60-72, доб.
Санкт-Петербург: +7 (812) 426-14-07, доб. 997
Регионы РФ: +7 (800) 500-27-29, доб. 669.
Заявки принимаются круглосуточно и каждый день. Либо воспользуйтесь онлайн формой.
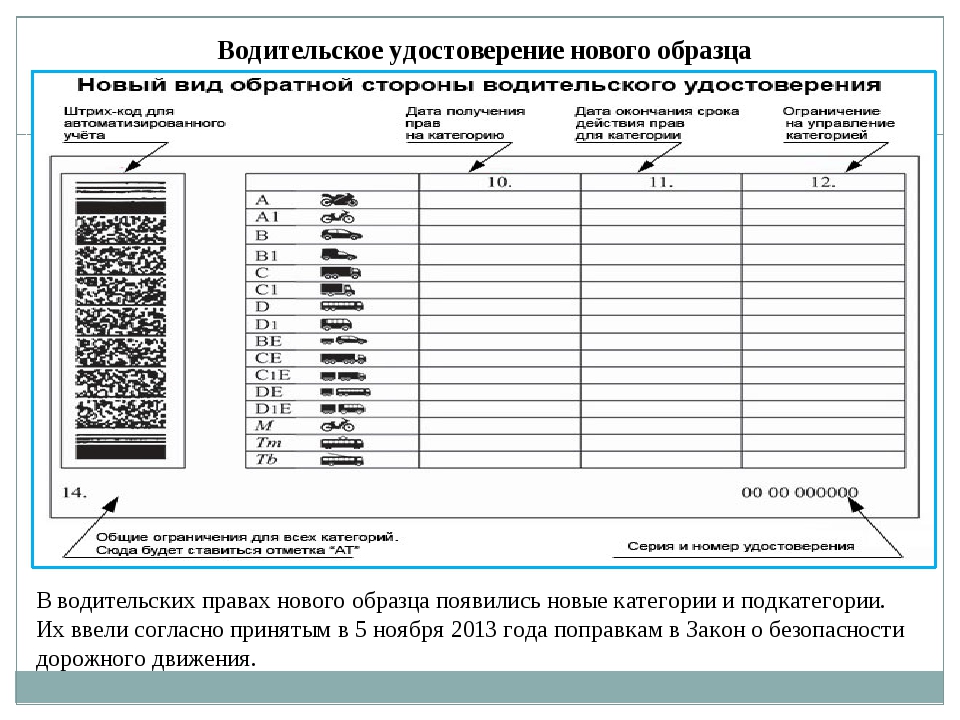
Новые водительские права 2019 года: что обозначают, расшифровка категорий
С расшифровкой категорий новых водительских прав 2019 года знакомы не все водители. Глобальные пертурбации в порядке выдачи этого документа произошли в РФ в 2013 году. Тогда были внесены изменения в категории и подкатегории удостоверения. Стал иным и вид документа.
Основные категории
Сразу стоит отметить нововведения:
- возрастной порог получения документа был снижен до 16 лет;
- допуски к управлению пассажирским автобусом могут получить водители, достигшие 21 года.
A
Позволяет управлять любыми видами мотоциклов, включая те, что оборудованы колясками. Если у водителя данная отметка была в удостоверении ранее, при замене или обновлении документа ему автоматически проставят категорию «А1».
B
Позволяет управлять машинами, совокупный вес которых не превышает 3,5 тонны, а максимальное число сидячих мест насчитывает 8 единиц. Если автомобиль эксплуатируется с прицепом, требуется открытие дополнительной категории «ВЕ». При наличии открытой «В» – «В1» присваивается автоматически.
С
Открывает доступ к управлению грузовыми ТС массой выше 3,5 тонны. Получив соответствующее разрешение, водитель спокойно может садиться за руль ТС, имеющих меньший вес, в том числе и обычных легковушек.
Некоторые подкатегории присваиваются автоматически при замене в/уЕсли грузовик эксплуатируется вместе с прицепом, общий вес которых превышает отметку 750 кг, необходимо дополнительно открывать категорию «CE». При замене удостоверения старого формата на новый к отметке «С» автоматически добавляется «С1».
D
Категория Д водительских прав – что это и чем можно управлять, имея данную метку в документах? Такой вопрос интересует многих новичков. Поясняем, ее наличие предоставляет возможность перевозить пассажиров в автобусах, оборудованных более чем 8-ю креслами, не считая самого шофера.
Если автобус эксплуатируется в сцепке с тяжелым прицепом, нужна будет категория «DЕ». Как и в случае с остальными вариантами, «D1» проставляется без каких-либо дополнительных проволочек, при условии замены старых прав на новые.
Водитель с категорией B не имеет права перевозить больше 8 пассажировМ
Что обозначает категория М водительских прав? Право на законных основаниях садиться за руль небольших мопедов и скутеров. Большинству граждан, имеющих удостоверения, открывать эту категорию не нужно. Соответствующая метка ставится в ГИБДД при разрешении управлять любыми другими ТС, начиная от легковушек и заканчивая фурами.
Тм
Открывает доступ к управлению таким видом транспорта, как трамваи.
Tb
Предназначена для водителей, желающих сесть за баранку троллейбуса.
У водителей троллейбусов стоит метка TbПеречень подкатегорий
Кроме основных категорий, в водительском удостоверении современного образца есть шесть разных подкатегорий.
А1
Позволяет управлять ТС сна двух колесах с движками объемом не более 125 куб. см. Максимальная мощность мотора средства передвижения не должна превышать 11 кВт.
В1
Открывает доступ к управлению квадроциклами и трициклами. Кстати, они могут эксплуатироваться по дорогам общего назначения.
С1
В эту подкатегорию входят авто с совокупной массой от 3,5 до 7,5 тонны.
Чтобы управлять квадроциклом, также нужно иметь разрешениеС1Е
Открывает возможность управления авто, входящими в категорию «С1» в сцепке с тяжелыми прицепами.
D1
Подразумевает управление автомобилями, имеющими более восьми, но менее 16 мест для посадки пассажиров.
D1E
Позволяет эксплуатировать транспортные средства, относящиеся к категории «D1» в сцепке с тяжелыми прицепами.
Как выглядит основной документ водителя в 2019 году?
Теперь в/у имеет указание на двух языках – русском и иностранном. Это было сделано специально, согласно международной Конвенции. Дублирование латиницей позволило сделать документ легитимным за пределами РФ.
Дублирование латиницей позволило сделать документ легитимным за пределами РФ.
При наличии любых других символов, транслитерация буквами латинского алфавита обязательна.
Новшеством в/у образца 2019 года является деление информации на пронумерованные цифрами пункты. Такой формат позволяет легче воспринимать указанные данные:
- место рождения водителя;
- его инициалы.
Фотография и подпись водителя должны быть четкими. В них нельзя вносить какие-либо изменения.
Новые водительские права имеют окрас, переходящий от розового к голубому. Сам бланк тщательно защищен:
- голограммами, которые видны под ультрафиолетом;
- водяными знаками.
Получить новое в/у любой гражданин может в случае:
- завершения срока действия прав;
- необходимости внесения изменений в личные данные;
- утраты прав или их нечитабельности;
- изменений в состоянии здоровья, например, присвоении группы по инвалидности;
- желания открыть новую категорию;
- необходимости заменить бланк по личным причинам, например, при выезде в страны Венского соглашения.

[totalpoll id=»5209″]
Заключение
Далеко не все автомобилисты знают расшифровку категорий новых водительских прав 2019 года. Указанные в бланке литеры дают право управления разными ТС. Документ нового формата содержит в себе следующую информацию:
- фамилию и имя водителя;
- дату рождения;
- дату выдачи;
- код или название сервисного центра, выдавшего документ;
- открытую категорию или подкатегорию прав.
Категории водительских прав в Беларуси — Автошкола
Категория водительских прав обозначает группу транспортных средств, которыми можно управлять, получив водительские права. Оно действительно 10 лет, после нужно заменять. Выдает Госавтоинспекция Беларуси человеку, прошедшему обучение и сдавшему теорию по ПДД и практику по вождению.
Есть несколько категорий и подкатегорий водительских прав:
- АМ – мопеды.
- А – мотоциклы.
- А1 – мотоциклы с объемом двигателя до 125 м3 и мощностью до 11 кВт.
- В – легковые автомобили и грузовые с массой менее 3,5 т, автобусы до 8 сидячих мест.
- С – грузовые автомобили массой более 3,5 т.
- D – пассажирские автобусы (больше 8 мест без учета водителя).
- ВЕ – транспортное средство категории «В» с общей массой не больше 3,5 т, а прицепа – больше 750 кг.
- СЕ – категория «С», прицеп тяжелее 750 кг.
- DE – категория «D», прицеп больше 750 кг.
- F – трамваи.
- I – троллейбусы.
Возраст
- 16 лет – можно получить права на мопед и легкий мотоцикл (АМ, А1).
- 18 лет – мотоциклы, легковые автомобили с подкатегориями (А, В, C).
- 21 год – автобусы, трамваи, троллейбусы с подкатегориями (D, I, F).
У белорусских водительских прав появился международный статус, когда Беларусь стала участницей Венской дорожной конвенции. Разрешено управлять транспортными средствами во многих странах Европы, подписавших конвенцию, и странах, состоящих в Таможенном союзе с нашей страной.
Если приехали из другой страны в Беларусь больше, чем на 3 месяца, – необходимо получить белорусское водительское удостоверение.
Как присваиваются дополнительные категории?
Если у водителя есть права на высшую категорию, дополнительная подготовка для более низкой не нужна: просто примут практический экзамен в ГАИ.
- Сдавших теоретический, практический экзамен на категорию «С» при желании автоматически допустят к практическому экзамену на «А» и «В», чтобы сразу открыть три категории.
- Сдавших категорию «В» допустят к практическому экзамену на «А», чтобы одновременно открыть удостоверение на вождение легковых автомобилей и мотоциклов.
- Прошедших переподготовку с «В» на «D» автоматически допускают к практическому экзамену на категорию «С».
- Получивших специальное или высшее образование, связанного с автомобилями, автоматически допускают к экзаменам для «А» и «В», в некоторых случаях и к «С». Нужно просто приложить к документам заверенные копию диплома и приложение к нему.
Сложно предугадать, что в жизни пригодится и за руль какого автомобильного устройства понадобится сесть. Но лучше тратить свое время и деньги на те категории, по которым будете постоянно практиковаться.
| №п/п | Наименование льготной категории | Взнос на капитальный ремонт | |
| процент скидки | площадь для расчета льготы | ||
| 1 | Герои СССР, РФ и полные кавалеры ордена Славы, не получающие ежемесячную денежную выплату | 100 | без ограничения по нормам |
| 2 | Пережившие супруги и родители Героев СССР, РФ и полных кавалеров ордена Славы, не получающие ежемесячную денежную выплату | 100 | без ограничения по нормам |
| 3 | Герои Соц. Труда и полные кавалеры ордена Трудовой Славы, не получающие ежемесячную денежную выплату | 100 | без ограничения по нормам |
| 4 | Инвалиды боевых действий, инвалиды в результате исполнения обязанностей военной службы и служебных обязанностей | 100 | соц. норма на 1 чел. |
| Семьи инвалидов боевых действий, инвалидов в результате исполнения обязанностей военной службы и служебных обязанностей | 50 | Занимаемая площадь за вычетом 33 кв.м | |
| 5 | Инвалиды ВОВ | 100 | соц. норма на 1 чел. |
| Семьи инвалидов ВОВ | 50 | Занимаемая площадь за вычетом 33 кв.м | |
| 6 | Участники ВОВ, проходившие военную службу в воинских частях, военно-учебных заведениях, не входивших в состав действующей армии в период ВОВ, являющиеся инвалидами; Участники боевых действий, приравненных к периоду ВОВ | 100 | соц. норма на 1 чел. |
| Семьи участников ВОВ, проходивших военную службу в воинских частях, военно-учебных заведениях, не входивших в состав действующей армии, являющихся инвалидами; семьи участников боевых действий, приравненных к периоду ВОВ | 50 | Занимаемая площадь за вычетом 33кв.м | |
| 7 | Участники ВОВ, проходившие военную службу в воинских частях, входивших в состав действующей армии | 100 | соц. норма на 1 чел. |
| Семьи участников ВОВ, проходивших военную службу в воинских частях, входивших в состав действующей армии | 50 | Занимаемая площадь за вычетом 33 кв.м | |
| 8 | Лица, работавшие на предприятиях, в организациях и учреждениях Ленинграда в период блокады с 08.09.41 по 27.01.44 и награжденные медалью «За оборону Ленинграда»; Инвалиды детства в результате боевых действий в период ВОВ | 50 | без ограничения по нормам |
| 9 | Лица, награжденные знаком «Жителю блокадного Ленинграда», признанные инвалидами | 50 | без ограничения по нормам |
| 10 | Ветераны боевых действий | 50 | без ограничения по нормам |
| 11 | Родители, супруги , не вступившие в повторный брак, умерших (погибших) инвалидов ВОВ и инвалидов боевых действий | 50 | без ограничения по нормам |
| 12 | Нетрудоспособные члены семьи умершего (погибшего) инвалида ВОВ и инвалида боевых действий, состоявшие на его иждивении и получающие пенсию по случаю потери кормильца | 50 | без ограничения по нормам |
| 13 | Супруги умерших (погибших) участников ВОВ, не вступившие в повторный брак | 50 | без ограничения по нормам |
| 14 | Родители умерших (погибших) участников ВОВ | 50 | без ограничения по нормам |
| 15 | Нетрудоспособные члены семьи умершего, (погибшего) участника ВОВ, состоявшие на его иждивении и получающие пенсию по случаю потери кормильца | 50 | без ограничения по нормам |
| 16 | Супруги умерших (погибших) ветеранов боевых действий , не вступившие в повторный брак и проживающие одиноко или с несовершеннолетними детьми, или с ребенком старше 18 лет, ставшим инвалидом до достижения им 18 лет, или с детьми, не достигшими 23 лет и обучающимися в образовательных учреждениях по очной форме обучения | 50 | без ограничения по нормам |
| 17 | Родители умерших (погибших) ветеранов боевых действий | 50 | без ограничения по нормам |
| 18 | Нетрудоспособные члены семьи умершего (погибшего) ветерана боевых действий, состоявшие на его иждивении и получающие пенсию по случаю потери кормильца | 50 | без ограничения по нормам |
| 19 | Члены семей военнослужащих, сотрудников органов внутренних дел и государственной безопасности, погибших или пропавших без вести при исполнении служебных обязанностей | 50 | без ограничения по нормам |
| 20 | Несовершеннолетние узники концлагерей и других мест принудительного содержания, созданных фашистами | 50 | без ограничения по нормам |
| 21 | Лица, подвергшиеся политическим репрессиям , являющиеся пенсионерами или инвалидами | 50 | соц. норма на семью |
| 22 | Лица, пострадавшие от политических репрессий, являющиеся пенсионерами или инвалидами | 50 | соц. норма на семью |
| 23 | Члены семей реабилитированных, пострадавших в результате репрессий, являющиеся пенсионерами или инвалидами | 50 | соц. норма на семью |
| 24 | Граждане, получившие заболевания, связанные с аварией на Чернобыльской АЭС | 50 | соц. норма на семью |
| 25 | Граждане, эвакуированные в 1986 г. из зоны отчуждения | 50 | соц. норма на семью |
| 26 | Граждане, переселенные из зоны отселения в 1986 г. и в последующие годы | 50 | соц. норма на семью |
| 27 | Граждане, принимавшие в 1986-1987г.г участие в работах по ликвидации последствий аварии на Чернобыльской АЭС | 50 | соц. норма на семью |
| 28 | Семьи граждан, умерших (погибших) в результате аварии на Чернобыльской АЭС | 50 | соц. норма на семью |
| 29 | Лица, получившие лучевую болезнь или ставшие инвалидами вследствие аварий на других (кроме Чернобыльской АЭС) атомных объектах | 50 | соц. норма на семью |
| 30 | Граждане из подразделений особого риска | 50 | соц. норма на семью |
| 31 | Семьи, потерявшие кормильца из числа лиц, действовавших в составе подразделений особого риска | 50 . | соц. норма на семью |
| 32 | Граждане,принимавшие участие в ликвидации последствий аварии на ПО «Маяк» | 50 | соц. норма на семью |
| 33 | Граждане, получившие заболевания вследствие аварии на ПО «Маяк», эвакуированные из районов, подвергшихся радиоактивному загрязнению | 50 | соц. норма на семью |
| 34 | Семьи, потерявшие кормильца вследствие аварии на ПО «Маяк» | 50 | соц. норма на семью |
| 35 | Граждане, пострадавшие от ядерных испытаний на Семипалатинском полигоне | 50 . | соц. норма на семью |
| 36 | Ветераны труда после назначения пенсии на основании закона «О трудовых пенсиях в Российской Федерации» от 17.12.2001 №173-ФЗ | 50 | соц. норма на семью |
| 37 | Ветераны военной службы и ветераны труда после назначения пенсии по основаниям, отличным от закона «О трудовых пенсиях в Российской Федерации» от 17.12.2001 №173-ФЗ, при достижении возраста, дающего право на пенсию по старости | 50 | соц. норма на семью |
| 38 | Дети-сироты и дети, оставшиеся без попечения родителей, лица из их числа | 100 | без ограничения по нормам |
| 39 | Труженики тыла | 50 | соц. норма на семью |
| 40 | Участники ВОВ, проходившие военную службу в воинских частях, военно-учебных заведениях, не входивших в состав действующей армии в период ВОВ, не являющиеся инвалидами | 50 | соц. норма на семью |
Коэффициент бонус-малус (КБМ) 2021
Коэффициент бонус-малус (КБМ) — коэффициент страховых тарифов в зависимости от наличия или отсутствия страхового возмещения, осуществленного страховщиками в предшествующий период, с 1 апреля предыдущего года до 31 марта включительно следующего за ним года при осуществлении обязательного страхования гражданской ответственности владельца транспортного средства.
При заключении договора ОСАГО страховая компания обязана использовать сведения о предыдущих периодах страхования, содержащиеся в автоматизированной информационной системе Российского союза автостраховщиков (АИС РСА).
- Таблица значений КБМ
№
Коэффициент КБМ на период КБМ
Коэффициент КБМ
0 страховых возмещений за период КБМ 1 страховое возмещение за период КБМ 2 страховых возмещения за период КБМ 3 страховых возмещения за период КБМ Более 3 страховых возмещений за период КБМ 1 2,45 2,3 2,45 2,45 2,45 2,45 2 2,3 1,55 2,45 2,45 2,45 2,45 3 1,55 1,4 2,45 2,45 2,45 2,45 4 1,4 1 1,55 2,45 2,45 2,45 5 1 0,95 1,55 2,45 2,45 2,45 6 0,95 0,9 1,4 1,55 2,45 2,45 7 0,9 0,85 1 1,55 2,45 2,45 8 0,85 0,8 0,95 1,4 2,45 2,45 9 0,8 0,75 0,95 1,4 2,45 2,45 10 0,75 0,7 0,9 1,4 2,45 2,45 11 0,7 0,65 0,9 1,4 1,55 2,45 12 0,65 0,6 0,85 1 1,55 2,45 13 0,6 0,55 0,85 1 1,55 2,45 14 0,55 0,5 0,85 1 1,55 2,45 15 0,5 0,5 0,8 1 1,55 2,45
Вопросы и ответы про КБМ
- От чего зависит КБМ?
Коэффициент бонус-малус (КБМ) определяется для каждого водителя транспортного средства индивидуально и влияет на стоимость договора ОСАГО. Для договоров обязательного страхования, не предусматривающих ограничение числа лиц, допущенных к управлению транспортным средством, владельцем которого является физическое лицо, страховой тариф рассчитывается с применением коэффициента КБМ, равного 1.
Значение КБМ сохраняется вне зависимости от смены страховой компании. Порядок определения и применения КБМ описан в разделе «Порядок определения КБМ».
- Как проверить текущее значение КБМ на сайте РСА?
Проверить текущее значение КБМ самостоятельно в автоматизированной информационной системе Российского союза автостраховщиков (АИС РСА) можно на сайте: перейти на сайт РСА.
- Как проверить текущее значение КБМ на нашем сайте?
Проверка осуществляется в автоматизированной информационной системе Российского Союза Автостраховщиков (АИС ОСАГО) в течение 10 календарных дней. Ответ будет направлен на указанный Вами адрес электронной почты.
1 Этап «Проверка КБМ в РСА»
- Зайдите в личный кабинет
- Внесите полис в личный кабинет
- Нажмите на кнопку «КБМ»
- Заполните форму и нажмите «Проверить»
- Ваш запрос на проверку КБМ будет направлен в РСА С 1 декабря 2015 года действует упрощенный порядок рассмотрения обращений граждан при их несогласии со значением КБМ, примененным по действующему или вновь заключаемому договору. При получении соответствующего заявления клиента страховая организация осуществляет проверку значения коэффициента КБМ в автоматизированной информационной системе Российского Союза Автостраховщиков (АИС ОСАГО), созданной в соответствии с требованиями Федерального закона «Об ОСАГО». Проверка осуществляется в течение 10 календарных дней. Если проверка дает значение КБМ, отличное от примененного по договору, страховщик осуществляет перерасчет страховой премии по действующему договору и применяет новое значение КБМ в договорах, которые будут заключены позднее.
2 Этап «Проверка КБМ нашими специалистами»
- Если в ответ Вам поступит ссылка, значит, по указанным данным РСА не смог осуществить автоматическую проверку
- Перейдите по ссылке в письме и прикрепите сканы документов
- Опишите Вашу ситуацию. Укажите в отношении каких транспортных средств Вы заключали договоры ОСАГО в компании Росгосстрах (государственный регистрационный знак, идентификационный номер), когда меняли водительское удостоверение (если у Вас нет скана, можно узнать данные в карточке водителя) или меняли фамилию
- В течение 30 дней мы направим ответ на указанный адрес электронной почты
- Если КБМ повлиял на стоимость полиса, приложите копию паспорта и реквизиты страхователя. Мы вернем Вам переплаченную часть страховой премии
- Замена водительского удостоверения (ВУ) и/или фамилии, имени и/или документа, удостоверяющего личность
Если вы поменяли водительское удостоверение и/или фамилию, имя и/или документ, удостоверяющий личность, необходимо внести изменения в действующий договор ОСАГО как можно скорее. Это необходимо для внесения корректных сведений в автоматизированную информационную систему Российского союза автостраховщиков (АИС ОСАГО) и присвоения правильного КБМ в будущем.
В соответствии с пунктом 8 ст.15 Федерального закона 40-ФЗ П: «В период действия договора ОСАГО страхователь обязан незамедлительно сообщать Страховщику в письменной форме об изменении сведений, указанных в заявлении о заключении договора страхования». В случае одновременного действия нескольких договоров ОСАГО, необходимо вносить изменения в каждый из этих договоров ОСАГО.
Написать заявление на внесение изменений можно в любом офисе ПАО СК «Росгосстрах». Внести изменения в электронный полис ОСАГО можно через Личный кабинет клиента.
- Порядок определения КБМ
С 1 апреля 2019 года КБМ рассчитывается один раз в год — 1 апреля и применяется в течение всего периода (с 1 апреля по 31 марта) для заключения любого договора.
Коэффициент КБМ водителя, являющегося владельцем транспортного средства — физическим лицом, или лицом, допущенным к управлению транспортным средством, владельцем которого является физическое или юридическое лицо, включая случаи, когда договор обязательного страхования не предусматривает ограничения количества лиц, допущенных к управлению транспортным средством (далее — КБМ водителя), в отношении которого в АИС ОСАГО содержатся сведения о договорах обязательного страхования, определяется на основании значения коэффициента КБМ, который был определен водителю на период КБМ, и количества страховых возмещений по всем договорам обязательного страхования, осуществленных страховщиками в отношении данного водителя и зарегистрированных в АИС ОСАГО в течение периода КБМ.
- Полис с ограниченным списком водителей
-
Общий порядок
По договору обязательного страхования, предусматривающему ограничение количества лиц, допущенных к управлению транспортным средством, КБМ определяется на основании сведений в отношении каждого водителя. КБМ присваивается каждому водителю, допущенному к управлению транспортным средством, указанным в договоре. При расчете страховой премии применяется наибольшее значение коэффициента КБМ. При отсутствии сведений о страховой истории водителю присваивается КБМ = 1.
- Страхователь, который является вписанным Водителем №1 с КБМ равным 0,9, вписал в полис ОСАГО водителя №2 с КБМ равным 1,4, т. к. по его вине была выплата страхового возмещения договору, окончившемуся не более года назад. Соответственно, размер страховой премии будет определяться по водителю №2, и размер премии будет увеличен в связи с меньшим коэффициентом водителя №2.
- Водитель №1 и водитель №2 имеют одинаковый КБМ 0,8. Страхователь вписал в полис ОСАГО водителя №2. Соответственно, факт добавления в полис второго водителя на КБМ по договору не повлияет, и страховая премия останется неизменной.
Если водитель ранее не был вписан в полис ОСАГО (например, только получил водительское удостоверение)
При отсутствии сведений в АИС РСА по указанным в договоре водителям им присваивается КБМ = 1.
- Водитель №1 получил права и через два дня купил транспортное средство. При оформлении договора ОСАГО такому водителю присваивается КБМ = 1.
- Полис без ограничений
-
Для договоров обязательного страхования, не предусматривающих ограничение числа лиц, допущенных к управлению транспортным средством, владельцем которого является физическое лицо, страховой тариф рассчитывается с применением коэффициента КБМ, равного 1.
- Если предыдущий договор был досрочно расторгнут
-
При заключении нового договора ОСАГО, КБМ будет равным КБМ, который был определен на 1 апреля текущего года.
- Если произошло ДТП
-
Если в результате ДТП вы являлись пострадавшей стороной, то выплата по данному ДТП никак не отразится на вашем классе аварийности (КБМ). Если вы стали виновником ДТП, то КБМ будет снижен только у того водителя, который был виновником ДТП.
- Перерыв в страховании 1 год и более
-
Согласно Указанию ЦБ №5000-у в части КБМ с 1 апреля 2019 года значение коэффициента не зависит от перерывов в страховании. Это означает, что с 1 апреля 2019 гражданин получает единый КБМ, который в дальнейшем применяется к нему во всех договорах ОСАГО и из-за перерыва не «аннулируется» (т.е. не превращается в 1).
Как поменять категорию земли — Полезные советы : Domofond.ru
У земли ИЖС масса преимуществ. На ней можно зарегистрироваться по конкретному адресу, получить свободный и законный доступ к воде, газу, электроэнергии и канализации и помощь муниципальных властей в обслуживании территории. Поэтому сменить категорию земли на ИЖС хотят многие, но далеко не всегда это возможно. Обо всех тонкостях рассказывает коммерческий директор проекта БТИ 2.0 Алексей Паршин.
bloodua/Depositphotos
Согласно законам Российской Федерации, все земли делятся на ряд категорий: населенных пунктов; сельхозназначения; промышленного и социального назначения, а также некоторые другие. Только на земельных участках первых двух категорий закон разрешает строить жилье, и только эти территории имеют все права, чтобы устроить комфортную жизнь.
Вид разрешенного использования (ВРИ) земельного участка под индивидуальное жилищное строительство актуален только для земель населенных пунктов, к примеру коттеджных поселков, где разрешены проживание и регистрация.
Как выбрать и купить участок под строительство?
На землях каких категорий можно строить, а на каких нельзя?
Другими словами, «категория земельного участка» и «вид разрешенного использования земельного участка» дают ответ на вопрос, какие объекты капитального строительства можно в законном порядке построить на этой земле.
Основная сложность — в генплане
Закон нашей страны не предусматривает переход земли из одной категории в другую по желанию собственника. Поменять ее с «сельхозназначения» на «земли, где можно возводить частный дом», не получится. Основанием для такого изменения может стать только новый утвержденный генплан территории. В этом плане администрация района должна предусмотреть такое изменение. Только в этом случае собственник имеет право подать ходатайство в администрацию о смене категории земельного участка.
Рассматривают ходатайство до двух месяцев, а после этого в течение еще пары недель выдается положительное решение или отказ.
Если ответ «да», то владелец участка получает на руки акт, в котором указываются:
- основания для изменения категории;
- границы, площадь и кадастровый номер участка;
- категория, к которой относилась земля, и категория, к которой она будет относиться теперь.
Разрешено ли строительство на землях СНТ?
Три критически важных нюанса при покупке участка под ИЖС
Главная причина отказа в смене категории земли
Вам откажут в смене категории участка, если участок расположен на удалении от черты населенного пункта и в планы администрации не входит развивать и расширять ближайший населенный пункт.
Еще до того, как запускать весь процесс, стоит учесть и другие факторы. Например, в смене категории откажут, если экологическая экспертиза оказалась отрицательной; если целевое назначение земли не соответствует землеустроительным документам; если участок относится к таким категориям, как пастбище, луг или нечто подобное.
Стоимость услуги и налоги
Во-первых, при изменении категории земли поменяется и налог на нее. Но если землю в другой статус не перевели, а на участке сельхозназначения разрешили построить жилой дом, то налоговая ставка останется прежней. Покрытие изменения кадастровой стоимости участка — вот самая затратная часть. И платить за это должен собственник. Сумма может достигать 30% от стоимости земли. На стоимость процедуры повлияют также размер участка, услуги по подготовке документов, создание проекта будущего дома, а если будет необходимо, то и экологическая экспертиза.
Могу ли я перевести свою землю в категорию ИЖС?
Почему поменять категорию земли проще, если рядом кладбище?
Иначе дело обстоит с видами разрешенного использования. Их поменять можно и даже проще, чем несколько лет назад. Если в вашей территориальной части Правил землепользования и застройки (ПЗЗ) вы как собственник участка имеете право изменить ВРИ, тогда просто следуйте инструкции.
1. Уточните зону вашего участка
Это вы можете сделать на сайте администрации вашей территории (района). Узнав наименование зоны земли, важно уточнить ее расшифровку и весь список допустимых видов разрешенного использования.
2. Соберите документы
Если в этом списке в ПЗЗ допустимый вид разрешенного использования — ИЖС, то, чтобы изменить ВРИ, вам потребуются:
- паспорт и его копия;
- выписка из ЕГРН, подтверждающая права собственника;
- заполненное заявление в адрес кадастровой палаты и Росреестра об изменении ВРИ.
Строим дома на земле СНТ – как их оформлять?
Я имею право построить на ИЖС многоквартирный дом?
3. Куда обращаться?
Вы можете все сделать самостоятельно или прибегнуть к услугам кадастрового инженера. Он составит заявление на изменение ВРИ, приложит скан ПЗЗ (документа градостроительного зонирования), а после отправит дело в кадастровую палату, которая меняет ВРИ. Заявление вы также можете подать самостоятельно через МФЦ. Важно, чтобы весь процесс проводил сам собственник земельного участка, его наследник или нотариально доверенное лицо.
4. Стоимость перевода
Изменение ВРИ бесплатное.
Текст подготовила Мария Гуреева
Не пропустите:
Как поменять категорию земли?
Чем отличается садовый дом от дачного?
Каким образом можно купить муниципальную землю под ИЖС?
Требуется ли разрешение на строительство сарая, гаража на участке?
Статьи не являются юридической консультацией. Любые рекомендации являются частным мнением авторов и приглашенных экспертов.
границ | Категория Декодирование визуальных стимулов на основе активности человеческого мозга с использованием двунаправленной рекуррентной нейронной сети для имитации двунаправленных информационных потоков в зрительной коре человека
Введение
В нейробиологии визуальное декодирование было важным способом понять, как и какая сенсорная информация кодируется и представляется в зрительной коре головного мозга. Функциональная магнитно-резонансная томография (фМРТ) является эффективным инструментом для отражения активности мозга, и модели вычисления визуального декодирования, основанные на данных фМРТ, привлекают значительное внимание на протяжении многих лет (Kamitani and Tong, 2005; Haynes and Rees, 2006; Norman et al., 2006; Naselaris et al., 2011; Нишимото и др., 2011; Хорикава и др., 2013; Ли и др., 2018; Пападимитриу и др., 2018). Категоризация, идентификация и реконструкция визуальных стимулов на основе данных фМРТ — три основных средства визуального декодирования. По сравнению с идентификацией и реконструкцией категоризация или декодирование категорий является обычным и возможным в области визуального декодирования, поскольку идентификация ограничивается набором данных фиксированного изображения, а точная реконструкция ограничивается простыми стимулами изображения.
Категориальное декодирование визуальных стимулов можно в основном разделить на три вида методов: (1) методы на основе классификатора, (2) методы на основе сопоставления шаблонов вокселей и (3) методы на основе сопоставления шаблонов признаков. Методы, основанные на классификаторах, выполняют декодирование категорий путем обучения статистического линейного или нелинейного классификатора для непосредственного изучения сопоставления конкретных воксельных паттернов в зрительной коре к категориям. В предыдущей работе (Cox and Savoy, 2003) использовались классификаторы линейной машины опорных векторов (SVM) (Chang and Lin, 2011) для различения воксельных паттернов, вызываемых каждой категорией.Кроме того, также использовались различные классификаторы, включая классификатор Фишера и классификатор k-ближайших соседей (Misaki et al., 2010; Song et al., 2011). Wen et al. (2017) использовали классификатор предварительно обученной сверточной нейронной сети (CNN) (LeCun et al., 1998) для декодирования категорий. Способы, основанные на сопоставлении шаблонов вокселей, должны вычислять корреляцию между вокселями, которые должны быть декодированы, и шаблоном шаблона вокселей каждой категории, и декодирование категории может выполняться в соответствии с максимальной корреляцией.Шаблон шаблона вокселей для каждой категории (Sorger et al., 2012) должен быть построен этими методами. Haxby et al. (2001) непосредственно использовали средства вокселей образцов той же категории, что и шаблон образца вокселей каждой категории. Kay et al. (2008) построили модель кодирования для прогнозирования шаблонов вокселей, используя эти образцы с соответствующей категорией, и взяли среднее значение предсказанных шаблонов вокселей в качестве шаблона шаблона вокселей для каждой категории. Методы, основанные на сопоставлении шаблонов признаков, реализуют декодирование путем сопоставления вокселей с конкретными функциями изображения, сравнения их с шаблонами шаблонов признаков каждой категории и, наконец, выбора категории с максимальной корреляцией.Третий способ зависит от промежуточного моста функций, и отображение вокселей на представления функций играет важную роль. Хорикава и Камитани (2017a) и Вен и др. (2018) построили шаблон паттерна признаков для каждой категории, усредняя предсказанные особенности CNN для всех стимулов изображения, принадлежащих к одной и той же категории. Среди этих исследований большое внимание привлекли исследования, основанные на иерархических характеристиках CNN (Agrawal et al., 2014; Güçlü and van Gerven, 2015).
В системе зрения человека зрительная кора головного мозга функционально организована в вентральный поток и спинной поток (Mishkin et al., 1983), а вентральная кора в основном отвечает за распознавание объектов. Анатомические исследования показали, что связи между брюшной корой были восходящими и нисходящими (Bar, 2003). Двунаправленные (прямые и обратные) соединения обеспечивают анатомическую структуру для двунаправленных информационных потоков в зрительной коре головного мозга. Прямые (Tanaka, 1996) и обратные потоки информации (Eger et al., 2006) играют разные роли в задачах распознавания. Визуальная информация течет от первичной зрительной коры к высокоуровневой зрительной коре, и тогда мы можем получить высокоуровневое семантическое понимание, которое известно как восходящий зрительный механизм (Logothetis and Sheinberg, 1996).Таким образом, деятельность зрительной коры в основном модулируется сенсорным входом. Помимо прямых входов, модуляция обратной связи от зрительной коры высокого уровня также может влиять на деятельность зрительной коры низкого уровня (Buschman and Miller, 2007; Zhang et al., 2008). Таким образом, визуальная информация течет от зрительной коры высокого уровня к зрительной коре низкого уровня, что известно как зрительный механизм сверху вниз (Beck and Kastner, 2009; McMains and Kastner, 2011; Shea, 2015).
Нисходящая роль в репрезентациях зрительной коры может быть облегчена и усилена с помощью задачи или цели (Beck and Kastner, 2009; Khan et al., 2009; Stokes et al., 2009; Гилберт и Ли, 2013). Например, Ли и др. (2004) продемонстрировали, что нейроны могут нести больше информации об атрибутах стимула, основываясь на нисходящем порядке, когда люди выполняют задачу. Хорикава и Камитани (2017a) показали, что категории воображаемых изображений могут быть декодированы, а Senden et al. (2019) пришли к выводу, что воображаемые буквы можно реконструировать по ранней зрительной коре головного мозга, что выявило тесное соответствие между зрительными ментальными образами и восприятием.Эти исследования предполагали, что визуальная информация может поступать из зрительной коры высокого уровня, чтобы модулировать представления коры низкого уровня, основываясь на нисходящем порядке. Более того, для тех, у кого нет задач или целей во время распознавания, визуальное внимание (Kastner and Ungerleider, 2000; Baluch and Itti, 2011; Carrasco, 2011), по-видимому, также может облегчить нисходящую роль в репрезентациях зрительной коры. Люди могут выбрать направление внимания на интересующие области на основе механизма визуального внимания после получения семантического понимания сенсорного ввода.Таким образом, семантическая информация также может поступать от зрительной коры высокого уровня, чтобы модулировать представления зрительной коры низкого уровня.
Хотя многие работы сосредоточены на взаимодействии (McMains and Kastner, 2011; Coco et al., 2014) между подходами снизу вверх и сверху вниз, все еще неясно, что такое «верхний», а что «нижний» в дискуссии. о нисходящем влиянии на восприятие (Teufel and Nanay, 2017). Однако текущие анатомические и функциональные роли восходящего и нисходящего зрительного механизма действительно указывают на некоторые важные точки зрения.Высокоуровневые зрительные коры могут формировать семантические представления или знания посредством иерархической обработки информации, основанной на восходящем способе, и представления в низкоуровневых зрительных кортиках также могут модулироваться на основе нисходящего способа. Кроме того, испытуемый видел один и тот же стимул изображения в нескольких повторных испытаниях в ходе эксперимента по визуальному декодированию, и испытуемый обращал внимание на эти интересные области после уловления основного значения стимула изображения, потому что люди могут сосредоточиться только на одной части. в то же время из-за конкуренции визуальных предубеждений (Desimone and Duncan, 1995).Во время обработки визуальной информации снизу вверх и сверху вниз визуальная информация часто перетекает от зрительной коры низкого уровня к зрительной коре высокого уровня и в обратном направлении. Таким образом, мы можем предположить, что двунаправленные информационные потоки несут семантические знания от зрительной коры высокого уровня. Следовательно, максимизация двунаправленных информационных потоков в зрительной коре будет иметь большое значение для декодирования категорий.
Однако три типа методов декодирования категорий игнорировали внутреннюю взаимосвязь между различными визуальными областями и рассматривали вокселы в выбранных зрительных корках в целом для подачи в модель декодирования.Поэтому мы ввели двунаправленные информационные потоки в нашу модель декодирования, чтобы охарактеризовать внутренние отношения. По сравнению с нейронными сетями прямого распространения, рекуррентные нейронные сети (RNN) (Mikolov et al., 2010; Graves et al., 2013; LeCun et al., 2015) могут очень хорошо работать с временными данными и широко используются при моделировании последовательностей. Общие RNN обычно имеют только одно направленное соединение от прошлых к будущим (или слева направо) узлов входной последовательности. Двунаправленные рекуррентные нейронные сети (BRNN) (Schuster, Paliwal, 1997; Schmidhuber, 2015) разделяют нейроны регулярных RNN на положительные и отрицательные направления.Два направления позволяют использовать входную информацию из прошлого и будущего текущего периода времени. Вдохновленные BRNN, мы рассматривали двунаправленные информационные потоки (одну пространственную последовательность) как одну поддельную временную последовательность. Поэтому мы предложили подавать вокселы в каждой визуальной области как один узел последовательности в модуль двунаправленного соединения (Hochreiter and Schmidhuber, 1997; Sutskever et al., 2014). Таким образом, выходные данные двунаправленного модуля RNN можно рассматривать как представления восходящего и нисходящего способов.Категория может быть предсказана с последующим полностью подключенным слоем softmax путем комбинирования двунаправленных представлений.
В этом исследовании наши основные вклады заключаются в следующем: (1) мы проанализировали недостатки существующих методов декодирования, основанных на восходящих и нисходящих визуальных механизмах, (2) мы предложили использовать BRNN для имитации двунаправленной информации. потоков для категориального декодирования визуальных стимулов, и (3) мы проанализировали, что двунаправленные информационные потоки устанавливают внутренние отношения между визуальными областями, связанными с категорией, и подтвердили, что моделирование внутренних отношений имело значение для категориального декодирования.
Материалы и методы
Экспериментальные данные
Набор данных, используемый в нашей работе, был построен на основе предыдущих исследований (Kay et al., 2008; Naselaris et al., 2009). Набор данных содержал визуальные стимулы, соответствующие данные фМРТ и метки категорий, состоящий из 1750 обучающих образцов и 120 проверочных образцов. Подробную информацию о визуальных стимулах и данных фМРТ можно получить из предыдущих исследований (Kay et al., 2008; Naselaris et al., 2009), а набор данных можно загрузить с http: // crcns.org / data-sets / vc / vim-1.
Визуальные стимулы
Визуальные стимулы состояли из последовательностей естественных фотографий, которые в основном были получены из знаменитого набора данных сегментации Беркли (Martin et al., 2001). Содержание фотографий включало животных, здания, продукты питания, людей, сцены в помещении, искусственные объекты, сцены на открытом воздухе и текстуры. Фотографии были преобразованы в оттенки серого и уменьшены до 500 пикселей. Фотографии (500 × 500 пикселей), представленные испытуемым, были получены путем кадрирования по центру, маскирования с циклом, размещения на сером фоне и добавления белого квадрата размером 4 × 4 пикселей в центральном положении.Всего в качестве визуальных стимулов было выбрано 1870 изображений, которые были разделены на 1750 и 120 изображений для обучения и проверки соответственно.
Схема эксперимента
Фотографии были представлены в последовательных четырехсекундных испытаниях. Каждое испытание содержало 1 с представления фотографии с частотой мигания 200 мс и 3 с представления серого цвета. Соответствующие данные фМРТ были собраны, когда два субъекта с нормальным зрением или зрением с поправкой на нормальное просмотрели фотографии и сфокусировались на центральном белом квадрате фотографий.Эксперимент с каждым испытуемым состоял из пяти сеансов сканирования, и каждый сеанс состоял из пяти тренировочных прогонов и двух проверочных прогонов. Семьдесят различных изображений были представлены два раза во время каждого тренировочного прогона, и 12 различных изображений были представлены 13 раз во время валидационного прогона. Изображения были выбраны случайным образом и были разными для каждого прогона. Таким образом, испытуемым были представлены все 1750 различных (5 сеансов × 5 запусков × 70) изображений и 120 различных (5 сеансов × 2 запусков × 12) изображений для обучения и проверки.
Сбор и предварительная обработка данных фМРТ
Система 4T INOVA MRI с квадратурной передающей / приемной поверхностной катушкой использовалась для получения данных fMRI. Функциональные и анатомические объемы мозга реконструировали с помощью программного пакета ReconTools https://github.com/matthew-brett/recon-tools. Время повторения (TR) составляло 1 с, а размер изотропного вокселя составлял 2 × 2 × 2,5 мм 3 в последовательности однократного градиента EPI. Полученные данные были подвергнуты серии предварительной обработки, включая фазовую коррекцию, синк-интерполяцию, коррекцию движения и совместную регистрацию с анатомическим сканированием.Что касается временных рядов предварительной обработки для каждого воксела, курсы времени отклика для вокселей были оценены на основе модели ограниченного базисного разделения (BRS) и оценки амплитуды (единственное значение) откликов вокселей для каждого из них. Изображение было получено путем деконволюции курсов времени отклика из данных временных рядов для повторных испытаний. Затем ответы были стандартизированы, чтобы улучшить согласованность ответов в сеансах сканирования. Вокселы были назначены каждой зрительной области на основе эксперимента по ретинотопному картированию, проведенного в отдельных сеансах.В набор данных были собраны вокселы в пяти областях интереса (V1, V2, V3, V4 и LO) от зрительной коры низкого до высокого уровня.
Ярлыки категорий
В дополнение к изображениям-стимулам и соответствующим данным фМРТ, пять опытных людей вручную пометили 1870 изображений, соответственно, в соответствии с тремя уровнями (5, 10 и 23 категории), и окончательные метки были получены путем голосования. Как показано на Рисунке 1, набор данных с трехуровневыми категориями может всесторонне подтвердить метод декодирования от крупнозернистого до мелкозернистого.
Рисунок 1. Трехуровневые метки с 5, 10 и 23 категориями. Трехуровневые категории были разработаны для проверки предлагаемого метода по разным параметрам, что может сделать сравнение более убедительным.
Образцы (кортежи данных) в обучении и проверке
Каждый образец включал один стимул изображения, соответствующие предварительно обработанные данные фМРТ и три метки для трехуровневых категорий. Размер стимула изображения был изменен на 224 × 224, чтобы соответствовать входным данным модели кодирования (см. Раздел «Визуальное кодирование на основе характеристик CNN»).Следует подчеркнуть, что данные фМРТ образцов не имеют измерения времени. Данные фМРТ удалили измерение времени посредством предварительной обработки, и каждый воксель в визуальных областях имел одно значение отклика для одного просматриваемого изображения. Сто вокселей (один вектор) в каждой визуальной области были выбраны на основе модели кодирования. Три метки в каждой выборке использовались для разных уровней категоризации. Поскольку двум испытуемым было показано 1750 обучающих изображений и 120 проверочных изображений, набор данных содержал 1750 обучающих образцов и 120 проверочных образцов для каждого испытуемого.
Обзор предлагаемого метода
Чтобы ввести двунаправленные информационные потоки в метод декодирования, мы использовали метод на основе BRNN для имитации восходящего и нисходящего поведения в системе человеческого зрения. Таким образом, в методе декодирования можно использовать не только информацию о каждой зрительной области, но и внутренние отношения между зрительными корками. Как показано на рисунке 2, предложенная модель включает части кодирования и декодирования. Для части кодирования мы можем получить соответствующие характеристики заданных стимулов изображения на основе преобладающего предварительно обученного ResNet-50 (He et al., 2016) модели и используют эти функции для соответствия каждому вокселю для построения модели кодирования по вокселям. В соответствии с характеристиками подгонки мы можем измерить важность каждого вокселя для всех визуальных областей. Мы выбрали фиксированное небольшое количество вокселей с более высокой предсказательной корреляцией для каждой визуальной области (V1, V2, V3, V4 и LO), чтобы предотвратить переобучение при последующем декодировании. Для части декодирования мы создали модуль RNN и использовали выбранные воксели каждой визуальной области в качестве пяти узлов входной последовательности, чтобы использовать как иерархические визуальные представления, так и двунаправленные информационные потоки в зрительной коре головного мозга.Наконец, мы объединили извлеченные функции двунаправленного модуля RNN в качестве входных данных последнего полностью подключенного слоя классификатора softmax для прогнозирования категории.
Рисунок 2. Предлагаемый способ. Иерархические особенности в глубокой сети использовались для прогнозирования воксельных паттернов в каждой визуальной области для направления кодирования. В зависимости от производительности можно выбрать ценные воксели, чтобы уменьшить размер вокселей до фиксированного числа. Чтобы предсказать категорию, последовательность вокселей, содержащая пять визуальных областей, подается в метод на основе BRNN для извлечения семантической информации из каждой визуальной области, и двунаправленная информация течет в зрительной коре головного мозга.
Раздел «Визуальное кодирование на основе функций CNN» знакомит с тем, как построить модель визуального кодирования на основе иерархических функций CNN. Раздел «Декодирование категории на основе функций BRNN» демонстрирует, как использовать BRNN для имитации двунаправленных информационных потоков для декодирования категории.
Визуальное кодирование на основе функций CNN
Мозг можно рассматривать как систему, которая нелинейно отображает сенсорную информацию в мозговой деятельности. Модель линеаризации кодирования (Naselaris et al., 2011) подтверждено и признано во многих исследованиях. Поэтому мы использовали линейную модель кодирования, которая состояла из нелинейного отображения пространства изображений в пространство признаков и линейного отображения пространства признаков в пространство активности мозга.
Нелинейное отображение из пространства изображения в пространство признаков на основе предварительно обученной модели ResNet-50
Многие работы (Agrawal et al., 2014; Yamins et al., 2014; Güçlü and van Gerven, 2015) показали, что иерархические визуальные особенности, извлеченные с помощью предварительно обученной модели CNN, продемонстрировали сильную корреляцию с нейронной активностью зрительной коры и визуальное кодирование, основанное на функциях CNN, получило лучшую производительность кодирования, чем те функции, разработанные вручную, такие как функции Габора (Kay et al., 2008). В этом исследовании мы использовали преобладающую глубокую сеть ResNet-50 для извлечения иерархических функций для визуального кодирования. Предварительно обученный ResNet-50 может распознавать 1000 типов естественных изображений (Русаковский и др., 2015) с ультрасовременной производительностью, которая демонстрирует, что сеть обладает богатыми и мощными представлениями функций.
В модели ResNet-50 50 скрытых слоев были уложены в иерархию снизу вверх. Помимо первого сверточного слоя, в сеть были включены четыре модуля (16 остаточных блоков, каждый из которых в основном состоит из 3 сверточных слоев) и последний полностью связанный слой softmax.Подробную конфигурацию сети можно увидеть в Таблице 1. По сравнению с предыдущей классической моделью AlexNet (Крижевский и др., 2012), ResNet-50 был намного глубже и содержал более мелкие иерархические функции, что полезно для кодирования. Чтобы снизить вычислительные затраты, мы выбрали только некоторые репрезентативные функции, включая результаты последней операции AvgPooling и 16 остаточных блоков для визуального кодирования. Таким образом, мы извлекли 17 видов функций для каждого стимула (1750 обучающих изображений и 120 проверочных изображений), чтобы изучить сопоставление конкретных видов функций с каждым вокселем в каждой визуальной области (V1, V2, V3, V4 и LO).В эксперименте предварительно обученную модель ResNet-50 можно загрузить с https://download.pytorch.org/models/resnet50-19c8e357.pth в рамках преобладающей инфраструктуры глубокой сети PyTorch (Ketkar, 2017).
Таблица 1. Структура модели ResNet-50.
Линейное отображение из пространства признаков в пространство действий на основе разреженной регрессии
Для каждого слоя модель линейной регрессии сопоставляет вектор признаков X с каждым вокселем y , и он определяется следующим образом:
у = Xw (1)
, где y — это матрица м на 1, а X — это матрица м на n , где м — количество обучающих выборок, а n — размер признака. вектор. w , матрица размером n на 1, является вектором взвешивания, который нужно обучить. В таблице 1 представлены размеры каждого выбранного вектора признаков. Количество обучающих выборок m (∼2 K) значительно меньше размерности признаков n (∼100 K), что является некорректной задачей. Таким образом, мы предположили, что каждый воксель может быть охарактеризован небольшим количеством признаков в векторе признаков, и регуляризованный w был разреженным, чтобы предотвратить переобучение при обучении отображению с высокой размерности вектора признаков на один воксель.На основании сделанного выше предположения основную проблему можно выразить следующим образом:
minww0 при условии Xw = y (2)
В этом исследовании мы использовали метод разреженной оптимизации, называемый регуляризованным поиском ортогонального соответствия (ROMP) (Needell and Vershynin, 2010), чтобы соответствовать шаблону вокселей. ROMP добавляет ортогональный элемент и групповую регуляризацию на основе алгоритма поиска совпадений (Mallat and Zhang, 1993). Подробности этих шагов алгоритма можно найти в Needell and Vershynin (2010).Мы построили модели кодирования вокселей, используя каждый из 17 различных уровней функций, и оптимизировали 17 линейных моделей для каждого воксела. Корреляция использовалась для измерения производительности кодирования, и была вычислена средняя корреляция верхних 200 вокселей для каждой визуальной области. Признаки, которые имели наилучшую корреляцию, были выбраны в качестве окончательных функций для кодирования этой визуальной области. На рисунке 3 представлена производительность кодирования для каждой визуальной области при использовании другого уровня функций. На рисунке особенности оптимального слоя отмечены кружком в соответствии с характеристиками кодирования.Наконец, мы выбрали 100 верхних вокселей для каждой визуальной области (V1, V2, V3, V4 и LO) в соответствии с характеристиками подгонки, и всего 500 вокселей для пяти областей были выбраны для декодирования следующей категории. На основе модели кодирования размер вокселей для каждой визуальной области был уменьшен до небольшого фиксированного числа, в то время как ценная информация была зарезервирована. Кроме того, производительность кодирования продемонстрировала, что функции низкого уровня лучше подходят для кодирования зрительной коры низкого уровня, а функции высокого уровня подходят для кодирования зрительной коры высокого уровня, что согласуется с предыдущим исследованием (Wen et al., 2018). Более того, мы проиллюстрировали, что выбранные воксели в визуальных областях, показанных на рисунке 4, указывают кластерное распределение для выбранных вокселей.
Рисунок 3. Производительность кодирования каждой визуальной области на основе функций ResNet-50. Для кодирования каждого вокселя в каждой визуальной области (V1, V2, V3, V4 и LO) использовалось семнадцать типов функций, и каждый узел представляет среднюю производительность кодирования 200 верхних вокселей с более высокой корреляцией. Каждый цвет представляет один тип визуальной области, а соответствующий «кружок» указывает на оптимальную производительность.Таким образом, можно выбрать оптимальные характеристики и выбрать 100 верхних вокселей для каждой визуальной области.
Рисунок 4. Распределение выбранных вокселей в визуальных областях. Белые линии разделяют пять визуальных областей (V1, V2, V3, V4 и LO). Каждая желтая точка представляет один воксель, который указывает, где находятся 100 выбранных вокселей каждой визуальной области. Эти выбранные воксели объединяются в кластеры вместо рассеянного распределения.
Декодирование категориина основе характеристик BRNN
Чтобы представить двунаправленные информационные потоки для моделирования отношений между зрительной корой, мы использовали преобладающий модуль долговременной краткосрочной памяти (LSTM) в методе декодирования для извлечения характеристик категории из пространственной последовательности, состоящей из пяти визуальных областей.Тогда категория может быть предсказана через полностью подключенный слой softmax.
Модуль РНН
Долгосрочная кратковременная память (Hochreiter, Schmidhuber, 1997; Sutskever et al., 2014) — известный модуль RNN во многих вариантах RNN (Cho et al., 2014; Greff et al., 2016), который широко используется в приложения последовательного моделирования. В этом исследовании мы использовали двунаправленный LSTM для характеристики двунаправленных информационных потоков в зрительной коре, а двунаправленный LSTM можно легко построить, добавив двунаправленные (прямые и обратные) соединения на основе LSTM.Таким образом, мы сначала рассмотрели LSTM, и за подробным описанием читатель может обратиться к следующему блогу: http://colah.github.io/posts/2015-08-Understanding-LSTMs/.
Долговременная кратковременная память обычно дополняется повторяющимися воротами, называемыми воротами «забыть», и может предотвратить исчезновение или взрыв ошибок обратного распространения. LSTM может изучать задачи, требующие памяти о событиях, которые произошли ранее. LSTM включает в себя три элемента (ворота «забыть», «вход» и «выход»), которые зависят от предыдущего состояния h t – 1 и текущего входа x t .Элемент «забыть» может управлять степенью забывания предыдущей информации в соответствии с f t , вычисленным с помощью уравнения (3), где σ представляет собой сигмовидную функцию для ограничения f t от 0 до 1. Таким образом , LSTM может включать в себя долговременную или краткосрочную память по мере необходимости, настраивая f t . «Входной» вентиль может контролировать, насколько подавать текущий входной сигнал x t в вычисление в соответствии с i t , вычисленным с помощью уравнения (4).«Выходной» вентиль может управлять, сколько информации должно быть выведено в соответствии с o t , вычисленным с помощью уравнения (5).
ft = σ (Wf⋅ [ht-1, xt] + bf) (3)
it = σ (Wi⋅ [ht-1, xt] + bi) (4)
ot = σ (Wo⋅ [ht-1, xt] + bo) (5)
На основе трех вентилей LSTM может вычислить состояние c t и h t по уравнениям (6) и (7), которые также являются выходом текущего вычисление.
ct = ft⋅ct-1 + it⋅ {𝑡𝑎𝑛ℎ (Wc⋅ [ht-1, xt] + bc)} (6)
ht = ot⋅𝑡𝑎𝑛ℎ (ct) (7)
Предлагаемая архитектура
Соединения в модуле RNN обычно имеют только одно направление (слева направо), но BRNN добавляет другое направление (справа налево), чтобы сделать модуль двунаправленным. На основе двунаправленного модуля LSTM мы представили архитектуру декодирования категорий.
Как показано на рисунке 5, входными данными для архитектуры являются вокселы, выбранные из пяти визуальных областей (V1, V2, V3, V4 и LO), которые составляют одну последовательность пробелов, следовательно, длина последовательности равна пяти.Согласно разделу «Визуальное кодирование на основе характеристик CNN» мы выбрали 100 вокселей для каждой визуальной области. Поскольку воксели не имеют измерения времени, 100 выбранных вокселей из каждой области рассматривались как один узел (вектор 100-D) входной последовательности, которая была передана в двунаправленный модуль LSTM. Таким образом, каждый узел также можно рассматривать как один момент (t 1 , t 2 , t 3 , t 4 и t 5 ) ложного временного ввода. По сути, мы использовали моделирование пространственной последовательности вместо временной последовательности для категории, и мы использовали двунаправленную LSTM для характеристики пространственных (несколько визуальных областей) серий отношений вместо временных рядов отношений для каждого воксела, что является важной характеристикой. нашего метода.
Рисунок 5. Модель декодирования категорий на основе модуля BRNN. Все визуальные области рассматриваются как одна последовательность, и модуль BRNN особенно хорош при моделировании последовательности. Красная линия указывает восходящие информационные потоки, а зеленая линия указывает нисходящие информационные потоки в зрительной коре. Комбинация характеристик с двух направлений используется для прогнозирования категории. Таким образом, информация из каждой визуальной области и двунаправленные информационные потоки в зрительной коре могут использоваться для декодирования.
Один уровень двунаправленного LSTM был добавлен в качестве входного уровня в архитектуре декодирования, чтобы охарактеризовать взаимосвязь во входной последовательности. Направления слева направо и справа налево характеризуют поведение снизу вверх и сверху вниз в системе человеческого зрения соответственно. Таким образом, на выходные характеристики одного узла влияют левые зрительные коры низкого уровня и правые зрительные коры высокого уровня. Следовательно, характеристики категории в каждой визуальной области и отношения между областями могут быть извлечены.Затем предложенный метод объединил выходные характеристики с двух направлений и подал их в последовательный полностью связанный слой softmax для прогнозирования категории. Кроме того, потеря фокуса (Lin et al., 2017) с гаммой 5.0 использовалась во время обучения для работы с трудными выборками. Что касается деталей архитектуры, входной узел был 100-D, а выход узла в каждом направлении LSTM был 16-D особенностью. Таким образом, для следующей классификации был получен 32-мерный признак, сочетающий два направления.Количество узлов в последнем полностью подключенном слое softmax составляло 5, 10 и 23 для трехуровневых меток соответственно. Мы добавили операцию выпадения со скоростью 0,5 за выводом двунаправленного LSTM, чтобы избежать переобучения. Наконец, в модели декодирования использовалась не только визуальная информация в каждой визуальной области, но и отношения между областями.
Предлагаемый метод может быть обучен сквозным образом с использованием алгоритмов, аналогичных стандартным RNN. Благодаря обучению в глубокой сетевой структуре PyTorch (Ketkar, 2017) двунаправленные информационные потоки, включая информацию о категориях, могут быть добыты на основе обучающих выборок.Во время обучения мы установили размер пакета равным 64 и использовали оптимизацию Адама, в которой скорость обучения составляла 0,001, а регуляризация веса была 0,001, для обновления параметров. На обучение в системе Ubuntu 16.04 с одной видеокартой NVIDIA Titan Xp потребовалось около 200 эпох.
Результаты
Классификаторы обычные линейные и нелинейные
Мы выбрали несколько классических классификаторов, включая дерево решений (DR), случайный лес (RF), AdaBoost (AB), линейный и нелинейный SVM.Декодирование трехуровневой категории (5, 10 и 23) было выполнено на основе этих традиционных классификаторов. Для декодирования с 5 категориями на рисунке 6 эти традиционные методы с использованием одной визуальной области были более точными, чем случайные, и даже первичные визуальные области полезны для декодирования семантической категории. Линейный тренд производительности декодирования от низкоуровневой к высокоуровневой зрительной коры также изображен на рисунке, который показывает, что производительность декодирования была улучшена. Это явление указывает на то, что больше семантической информации было получено из визуальных областей более высокого уровня.Кроме того, эти классические классификаторы обеспечивают лучшую производительность декодирования, когда все визуальные области используются вместо одной визуальной области, что указывает на то, что представления категории в разных визуальных областях дополняют друг друга. Результаты двух других уровней (10 и 23 категории) декодирования продемонстрировали аналогичное явление, которое показано на рисунках 7, 8. Кроме того, были рассчитаны среднее значение и дисперсия точности декодирования по результатам пяти повторных экспериментальных тестов с теми же гиперпараметрами. и нанесены на рисунки 6–8.Следует отметить, что дисперсия устойчивого линейного и нелинейного SVM и классификатора AB была равна нулю. Из рисунков видно, что точность декодирования SVM была выше, чем у других методов (DR, RF и AB), а производительность линейной и нелинейной SVM была аналогичной. Кроме того, эффективность S1 была выше, чем у S2, что согласуется с предыдущими исследованиями (Kay et al., 2008).
Рисунок 6. Расшифровка пяти категорий с помощью обычных классификаторов.Представлены точности различных обычных классификаторов при использовании только одной визуальной области и всех визуальных областей («V»). Можно наблюдать распределенные, иерархические и дополнительные представления семантической категории в системе человеческого зрения (подробный анализ в разделе «Обсуждение»).
Рисунок 7. Расшифровка 10 категорий с помощью обычных классификаторов.
Рисунок 8. Расшифровка 23 категорий с помощью обычных классификаторов.
Полностью подключенная нейронная сеть
В дополнение к традиционным классификаторам в разделе «Обычные линейные и нелинейные классификаторы» также был протестирован метод полносвязной нейронной сети (NN). Чтобы сравнить и проверить эффект моделирования двунаправленных информационных потоков, в методе NN использовалась архитектура, аналогичная предложенному методу, за исключением модуля RNN. В частности, метод NN имел три полностью связанных слоя. Количество нейронных узлов каждого слоя составляло 500, 64 и 32 соответственно.«500» было получено из комбинации выбранных вокселей в пяти визуальных областях. Выходы последнего полностью подключенного слоя softmax были 5-D, 10-D и 23-D для трехуровневых меток соответственно. Подобные гиперпараметры использовались во время тренировки. Таким образом, разница между методами на основе NN и BRNN заключалась в том, моделировались ли двунаправленные информационные потоки. Из рисунка 9 видно, что метод NN имеет лучшие или сравнительные характеристики относительно линейных и нелинейных методов SVM.Мы проанализировали преимущества мощной нелинейной способности нейронных сетей.
Рисунок 9. Количественное сравнение производительности декодирования для разных методов. Обычные методы и метод NN могут задействовать все визуальные области. Однако метод NN с мощной нелинейной способностью обеспечивает более высокую точность. Методы на основе BRNN с мощными нелинейными возможностями также могут использовать дополнительную информацию (двунаправленные информационные потоки), что обеспечивает лучшую производительность.
Предлагаемый метод
Как показано на рисунке 9, предложенный нами метод имел лучшую производительность для всех трех уровней декодирования категорий, поскольку он может дополнительно использовать двунаправленные информационные потоки в зрительной коре головного мозга. В таблице 2 представлена точность нашего метода, и точность декодирования по 5, 10 и 23 категориям достигла 60,83 ± 1,17%, 46,17 ± 0,42% и 39,50 ± 0,85% соответственно. Предложенный метод улучшился более чем на 5% по сравнению с другими лучшими методами.Аналогичные результаты для субъекта S2 можно найти в таблице 3. Для подтверждения статистической значимости мы вычислили соответствующие значения p для измерения разницы между предложенным методом и другими классификаторами в таблице 4. Он показал, что большинство значений значимости достигнуто. более высокий уровень ( P <0,001), что подтвердило значимость предлагаемого метода. Более того, минимальные значения значимости для каждого уровня категории были подчеркнуты в таблице 4, а значения значимости находились между ( P <0.01) и ( P <0,05), которые продемонстрировали приемлемую статистическую значимость. Подчеркнутые значения указывают на то, что предлагаемый нами метод показал значимость, даже несмотря на то, что использовались более строгие сравнения, в которых мы сравнивали предлагаемый метод с лучшими из всех других методов. Кроме того, на Рисунке 10 представлена матрица неточностей, отражающая подробные результаты классификации, и показано, что большинство образцов классифицированы правильно. Однако класс «текстура» показал худший результат, и мы представили два изображения, соответствующие данные фМРТ которых были классифицированы неправильно.Один был ошибочно отнесен к классу «естественный», а другой - к классу «созданный руками человека». Визуальные атрибуты двух изображений действительно были похожи на атрибуты изображений, принадлежащих к «естественным» и «искусственным» классам. Более того, классы «человек» и «животное» легко перепутать, что может быть результатом схожести визуальных атрибутов между классами «человек» и «животное».
Таблица 2. Количественное сравнение характеристик декодирования разными методами для субъекта S1.
Таблица 3. Количественное сравнение характеристик декодирования различными методами для субъекта S2.
Таблица 4. Статистическая значимость предлагаемого нами метода по сравнению с другими методами для испытуемых S1 и S2.
Рис. 10. Нормализованная матрица неточностей результатов и два примера ошибочной классификации для предложенного метода. Нормализованная матрица путаницы представляет подробную ошибочную классификацию, и два образца изображений используются для анализа класса («текстуры»), который имеет худшие характеристики классификации.
Эффект прямого, обратного и двунаправленного подключений
Кроме того, мы сравнили точность модуля RNN при использовании прямого, обратного и двунаправленного соединений. Двунаправленные соединения включали прямые и обратные соединения. Прямые связи характеризовали восходящие информационные потоки, а обратные связи характеризовали нисходящие информационные потоки в визуальных областях. Мы сравнили двунаправленные соединения (двунаправленный LSTM) с прямыми соединениями (LSTM с входом V1 → V 2 → V 3 → V 4 → последовательность LO), обратными соединениями (LSTM с входом LO → V 4 → V 3 → V2 → V1 последовательность), и никаких повторяющихся соединений (полностью связанный слой с вводом целых визуальных областей в целом).Соответствующие результаты были представлены в Таблице 5. Мы видим, что метод на основе LSTM («→ •»), который характеризует восходящие информационные потоки, ведет себя лучше, чем метод NN без повторяющихся соединений и LSTM («←≤») — на основе метода, характеризующего нисходящие информационные потоки. Тем не менее, использование двунаправленных соединений по-прежнему давало преимущества, поскольку было охарактеризовано больше взаимосвязей и использовалось больше визуальной информации. Двунаправленные методы на основе LSTM в целом показали лучшие результаты в соответствии со средним значением в таблице 5 за счет комбинирования соединений LSTM («→ •») и LSTM («←»).Мы также вычислили значения значимости, чтобы измерить разницу между LSTM («→ •») и двунаправленным LSTM («→ • и ←»). Для субъекта 1 значения значимости для декодирования по 5, 10 и 23 категориям составили 7,83 × 10 –4 , 7,72 × 10 –3 и 4,34 × 10 –5 , соответственно. Для субъекта 2 значения значимости для декодирования по 5, 10 и 23 категориям составили 3,07 × 10 –1 , 2,41 × 10 –2 и 5,31 × 10 –3 , соответственно. Эти результаты показали определенное различие между LSTM («→ •») и двунаправленным LSTM («→ • и ←»), а точность задачи декодирования для субъекта 1 имеет более высокие значения значимости, чем для субъекта 2.В заключение, одиночные соединения LSTM («←») вели себя немного хуже, чем метод на основе NN, но улучшение подтвердило роль LSTM («←»). Следовательно, для декодирования необходимы двунаправленные соединения, характеризующие восходящие и нисходящие информационные потоки.
Таблица 5. Сравнение того, используются ли прямые, обратные и двунаправленные соединения для модуля RNN.
Обсуждение
Известно, что зрительное декодирование предназначено для изучения того, что существует в зрительной коре головного мозга, но легче исследовать паттерн визуальных представлений в системе человеческого зрения.Таким образом, мы пришли к выводу о некоторых существующих моментах и суммировали сходства и различия между нашим методом и другими. Кроме того, были обсуждены методы визуального декодирования на основе CNN и RNN, чтобы продемонстрировать преимущества и ограничения предлагаемого нами метода, и был представлен наш вклад в эту область.
Некоторое соответствие с предыдущими исследованиями
Известно, что низкоуровневые и высокоуровневые функции глубоких сетей сосредоточены на подробной и абстрактной информации соответственно (Mahendran and Vedaldi, 2014).С точки зрения визуального кодирования, рисунок 3 показывает, что низкоуровневые и высокоуровневые функции подходят для кодирования зрительной коры низкого и высокого уровня соответственно, что было показано в серии предыдущих исследований (Güçlü and van Gerven, 2015; Eickenberg et al., 2016; Horikawa, Kamitani, 2017b). С точки зрения визуального декодирования рисунки 6–8 нашего исследования демонстрируют линейное улучшение от зрительной коры низкого уровня к зрительной коре высокого уровня, что может быть дополнением к методам визуального кодирования на основе CNN для поддержки иерархических представлений в визуальном восприятии. коры.
Когда только одна конкретная визуальная область используется в разных классификаторах, производительность декодирования категории лучше, чем случайная, и даже визуальные области низкого уровня могут вносить вклад в декодирование категории, что указывает на то, что визуальные области низкого уровня могут содержать визуальную информацию о категориях . Таким образом, как и в предыдущей работе (Haxby et al., 2001; Cox and Savoy, 2003), можно сделать вывод о распределенных представлениях категорий в зрительной коре головного мозга. Например, Haxby et al. (2001) продемонстрировали, что в вентральной коре головного мозга были распределены изображения лиц и предметов.Основываясь на двунаправленных информационных потоках, мы предположили, что распределенные представления могут быть вызваны динамическими информационными потоками. Визуальная информация из зрительных областей низкого уровня может перетекать в зрительные области высокого уровня, а визуальная информация из зрительных областей коры верхнего уровня также может поступать в зрительные области коры нижнего уровня. Следовательно, зрительные области в вентральной коре являются интерактивными, что может способствовать распределению репрезентаций в зрительной коре.
Результаты показывают, что производительность декодирования с использованием пяти визуальных областей превосходит использование только одной отдельной области.Улучшение подтверждает, что эти представления в различных визуальных областях не являются избыточными, а содержат различную информацию. Результаты кодирования, основанные на иерархической CNN (см. Рисунок 3), показали, что низкоуровневые функции подходят для кодирования первичной зрительной коры, а высокоуровневые функции более полезны для кодирования высокоуровневой зрительной коры. Учитывая, что низкоуровневые и высокоуровневые функции глубокой сети сосредоточены на подробной и абстрактной информации (Mahendran and Vedaldi, 2014), улучшение дополняет точку зрения о том, что низкоуровневые зрительные коры в основном обрабатывают низкоуровневые представления (края, текстуры , и цвет) и что высокоуровневые зрительные коры в основном отвечают за высокоуровневые репрезентации (форма и объект).Более того, дополнительные изображения указывают на то, что следует рассмотреть больше визуальных областей. Однако это исследование охватывает только пять зрительных областей, что является ограничением, а в некоторых предыдущих исследованиях даже упоминается меньшее количество зрительных корковых областей (Senden et al., 2019). Следовательно, следующим направлением может стать использование большего количества визуальных областей в методе декодирования и моделирование более сложных отношений в визуальных областях.
Корреляционные представления о категории в зрительной коре
За исключением иерархических, распределенных и дополнительных представлений о категориях в зрительной коре, результаты на рисунке 9 продемонстрировали, что мы можем получить улучшение примерно на 5% после введения двунаправленных информационных потоков и моделирования внутренних отношений в методе декодирования, что указывает на то, что взаимосвязь между визуальные области могут содержать семантическую информацию категорий и могут способствовать декодированию.Это показывает, что эти зрительные области связаны, а представления категорий в зрительной коре коррелятивны. Соответствующие представления категорий означают, что отношения между визуальными областями содержат атрибуты категорий. Поскольку мы не нашли литературы, в которой моделировались бы корреляционные представления для декодирования категорий из данных фМРТ, мы попытались проанализировать происхождение явления в соответствии с двунаправленными информационными потоками. А именно, семантическое знание сначала формируется посредством восходящей иерархической обработки сенсорной информации.Затем семантическая информация может поступать от зрительной коры высокого уровня для модуляции нейронной активности зрительной коры низкого уровня из-за задачи или внимания. Таким образом, мы можем заключить, что семантическая информация, содержащаяся в отношении, происходит от визуальной обработки снизу вверх и визуальной модуляции сверху вниз, а отношение связано с категориями из-за эффекта нисходящего способа. Современные методы, такие как преобладающие методы на основе CNN, не могут моделировать визуальный механизм сверху вниз и обычно учитывают только иерархические представления.
Отличие от преобладающих CNN и RNN на основе методов визуального декодирования
Целью нашего исследования является прямое декодирование категорий из вокселей (активности фМРТ) с использованием классификатора на основе модуля RNN. Известно, что CNN очень эффективны для задач визуального распознавания за счет извлечения иерархических и мощных функций из 2D-изображений. Таким образом, CNN особенно подходят для визуального кодирования, но не для классификации вокселей (1D). Как показано в разделе «Визуальное кодирование на основе характеристик CNN», функции, извлеченные CNN, используются для кодирования вокселей для выбора ценных вокселей.Кроме того, CNN могут выполнять декодирование косвенным способом, называемым «методами на основе сопоставления шаблонов признаков» (Han et al., 2017; Horikawa and Kamitani, 2017a), который существенно отличается от нашего метода под названием «Методы на основе классификаторов, », Который является наиболее прямым способом декодирования. Кроме того, своего рода «методы, основанные на сопоставлении шаблонов признаков», берут целые визуальные области в целом и сопоставляют их с функциями CNN, что затрудняет использование внутренних отношений между вокселями.Однако RNN обычно используются для моделирования данных последовательности, а методы на основе RNN (Spampinato et al., 2017; Shi et al., 2018) могут характеризовать данные с измерением времени в области визуального декодирования. Например, Spampinato et al. (2017) предложили использовать RNN для извлечения признаков из данных ЭЭГ для декодирования, и они использовали модуль LSTM для характеристики временных рядов взаимосвязи. В качестве улучшения мы использовали модуль LSTM, чтобы охарактеризовать пространственную (несколько визуальных областей) серию отношений, поскольку измерение времени для данных фМРТ обычно не слишком сильно учитывается в области визуального кодирования и декодирования.Более конкретно, их последовательность состоит из разных временных точек для каждого воксела, но последовательность для наших RNN состоит из вокселей в разных визуальных областях, что является существенным различием между нашим методом и другими основанными на RNN методами. В заключение, наш метод является прямым и новым, потому что мы используем моделирование пространственной последовательности вместо временной последовательности для категории. Таким образом, следующим направлением визуального декодирования может быть характеристика пространственно-временной последовательности вокселей в визуальных областях.
Заключение
В этом исследовании мы проанализировали недостатки существующих методов декодирования с точки зрения двунаправленных информационных потоков (визуальные механизмы снизу вверх и сверху вниз). Чтобы охарактеризовать двунаправленные информационные потоки в зрительной коре, мы использовали модуль BRNN для моделирования пространственного ряда отношений вместо общего временного ряда отношений. Мы рассматривали выбранные воксели каждой визуальной области (V1, V2, V3, V4 и LO) как один узел в пространственной последовательности, которая подавалась в BRNN для дополнительного извлечения функций взаимосвязи, связанных с категорией, для повышения производительности декодирования.Мы проверили наш предложенный метод на наборе данных с тремя уровнями меток категорий (5, 10 и 23). Экспериментальные результаты показали, что предложенный нами метод позволяет получать более точные результаты декодирования, чем другие линейные и нелинейные классификаторы, при этом подтверждая статистическую значимость двунаправленных информационных потоков для декодирования категорий. Вдобавок, основываясь на экспериментальных результатах, мы пришли к выводу, что репрезентации в зрительной коре были иерархическими, распределенными и дополнительными, что согласуется с предыдущими исследованиями.Что еще более важно, мы проанализировали, что двунаправленные информационные потоки в зрительной коре делают отношения между областями, содержащими представления категорий, и могут быть успешно использованы на основе BRNN, которую мы назвали коррелятивными представлениями категорий в зрительной коре.
Авторские взносы
KQ участвовал во всех этапах исследовательского проекта и написании статей. JC разработал процедуры общих экспериментов. LW способствовал идее декодирования на основе BRN.CZ внесла свой вклад в реализацию идеи. Л.З. участвовал в подготовке статьи, рисунков и диаграмм. LT ввел восприятие иерархических, распределенных, дополнительных и коррелятивных представлений в зрительной коре. BY предложил идею и написание.
Финансирование
Эта работа была поддержана Национальным планом ключевых исследований и разработок Китая (№ 2017YFB1002502) и Национальным фондом естественных наук Китая (№№ 61701089 и 162300410333).
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Список литературы
Агравал П., Стэнсбери Д., Малик Дж. И Галлант Дж. Л. (2014). Пиксели в воксели: моделирование визуального представления в человеческом мозге. arXiv препринт arXiv: 1407.5104.
Google Scholar
Бушман, Т.Дж., И Миллер, Э. К. (2007). Контроль внимания сверху вниз по сравнению с контролем снизу вверх в префронтальной и задней теменной области коры. Наука 315, 1860–1862. DOI: 10.1126 / science.1138071
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Chang, C.-C., and Lin, C.-J. (2011). «Транзакции ACM в интеллектуальных системах и технологиях (TIST)» в LIBSVM: Библиотека для опорных векторных машин , Vol. 2, (Нью-Йорк, Нью-Йорк: ACM Press). DOI: 10,1145 / 1961189.1961199
CrossRef Полный текст | Google Scholar
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., et al. (2014). Изучение представлений фраз с использованием кодировщика-декодера RNN для статистического машинного перевода. arXiv препринт arXiv: 1406.1078.
Google Scholar
Коко, М. И., Малькольм, Г. Л., и Келлер, Ф. (2014). Взаимодействие механизмов снизу вверх и сверху вниз в визуальном руководстве во время именования объектов. Q. J. Exp. Psychol. 67, 1096–1120. DOI: 10.1080 / 17470218.2013.844843
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кокс, Д. Д., и Савой, Р. Л. (2003). Функциональная магнитно-резонансная томография (фМРТ) «чтение мозга»: обнаружение и классификация распределенных паттернов активности фМРТ в зрительной коре головного мозга человека. Neuroimage 19, 261–270. DOI: 10.1016 / s1053-8119 (03) 00049-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Дезимоне, Р.и Дункан Дж. (1995). Нейронные механизмы избирательного зрительного внимания. Annu. Rev. Neurosci. 18, 193–222. DOI: 10.1146 / annurev.neuro.18.1.193
CrossRef Полный текст | Google Scholar
Эгер, Э., Хенсон, Р., Драйвер, Дж., И Долан, Р. Дж. (2006). Механизмы облегчения нисходящего восприятия визуальных объектов, изучаемых с помощью фМРТ. Cereb. Cortex 17, 2123–2133. DOI: 10.1093 / cercor / bhl119
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Айкенберг, М., Грамфорт, А., Вароко, Г., Тирион, Б. (2016). Видеть все: слои сверточной сети отображают функции зрительной системы человека. Нейроизображение 152, 184–194. DOI: 10.1016 / j.neuroimage.2016.10.001
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Грейвс А., Мохамед А.-Р. и Хинтон Г. (2013). «Распознавание речи с помощью глубоких рекуррентных нейронных сетей», в Акустика, обработка речи и сигналов (ICASSP), 2013 Международная конференция IEEE , (Ванкувер, Британская Колумбия: IEEE), 6645–6649.
Google Scholar
Грефф К., Шривастава Р. К., Коутник Дж., Стойнебринк Б. Р. и Шмидхубер Дж. (2016). LSTM: поисковая космическая одиссея. IEEE Trans. Neural Netw. Учить. Syst. 28, 2222–2232. DOI: 10.1109 / TNNLS.2016.2582924
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Güçlü, U., и van Gerven, M.A. (2015). Глубокие нейронные сети обнаруживают градиент сложности нейронных представлений в вентральном потоке. Дж.Neurosci. 35, 10005–10014. DOI: 10.1523 / JNEUROSCI.5023-14.2015
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хан, К., Вэнь, Х., Ши, Дж., Лу, К.-Х., Чжан, Ю., и Лю, З. (2017). Вариационный автоэнкодер: неконтролируемая модель для моделирования и декодирования активности фМРТ в зрительной коре. bioRxiv 214247. doi: 10.1016 / j.neuroimage.2019.05.039
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хэксби, Дж. В., Гоббини, М.И., Фьюри, М. Л., Ишаи, А., Схоутен, Дж. Л., и Пьетрини, П. (2001). Распределенные и перекрывающиеся изображения лиц и предметов в вентральной височной коре. Наука 293, 2425–2430. DOI: 10.1126 / science.1063736
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хе К., Чжан Х., Рен С. и Сун Дж. (2016). «Глубокое остаточное обучение для распознавания изображений», в материалах конференции IEEE по компьютерному зрению и распознаванию образов , Лас-Вегас, Невада, 770–778.
Google Scholar
Хорикава, Т., и Камитани, Ю. (2017b). Иерархическое нейронное представление объектов сновидения, выявленных путем декодирования мозга с помощью глубоких нейросетевых функций. Фронт. Комп. Neurosci. 11: 4. DOI: 10.3389 / fncom.2017.00004
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кастнер, С., Унгерлейдер, Л. Г. (2000). Механизмы зрительного внимания в коре головного мозга человека. Annu. Rev. Neurosci. 23, 315–341.
PubMed Аннотация | Google Scholar
Кеткар, Н. (2017). «Введение в pytorch», в Deep Learning with Python , ed. Н. Кеткар (Беркли, Калифорния: Апресс), 195–208. DOI: 10.1007 / 978-1-4842-2766-4_12
CrossRef Полный текст | Google Scholar
Хан, Ф. С., Ван Де Вейер, Дж., И Ванрелл, М. (2009). «Цветовое внимание сверху вниз для распознавания объектов», в материалах Труды 12-й Международной конференции IEEE 2009 г. по компьютерному зрению: IEEE , Киото, 979–986.
Google Scholar
Крижевский А., Суцкевер И., Хинтон Г. Э. (2012). «Классификация ImageNet с глубокими сверточными нейронными сетями», Международная конференция по системам обработки нейронной информации, , Невада, 1097–1105.
Google Scholar
ЛеКун, Ю., Ботту, Л., Бенжио, Ю., и Хаффнер, П. (1998). Применение градиентного обучения для распознавания документов. Proc. IEEE 86, 2278–2324. DOI: 10.1109 / 5.726791
CrossRef Полный текст | Google Scholar
Ли, К., Сюй Дж. И Лю Б. (2018). Расшифровка естественных изображений вызванных активностью мозга с использованием моделей кодирования с обратимым отображением. Neural Netw. 105, 227–235. DOI: 10.1016 / j.neunet.2018.05.010
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Лин, Т.-Й., Гоял, П., Гиршик, Р., Хе, К., и Доллар, П. (2017). «Потеря фокуса для обнаружения плотных объектов», в материалах Труды международной конференции IEEE по компьютерному зрению , Венеция, 2980–2988.
Google Scholar
Махендран А., Ведальди А. (2014). «Понимание представлений глубоких изображений путем их инвертирования», в материалах конференции IEEE по компьютерному зрению и распознаванию образов , Колумбус, Огайо, 5188–5196.
Google Scholar
Маллат, С., Чжан, З. (1993). Сопоставление преследования с частотно-временными словарями. Технический отчет. Courant Inst. Математика. Sci. N. Y. 41, 3397–3415. DOI: 10.1109 / 78.258082
CrossRef Полный текст | Google Scholar
Мартин, Д., Фаулкс, К., Тал, Д., и Малик, Дж. (2001). «База данных сегментированных природных изображений человека и ее применение для оценки алгоритмов сегментации и измерения экологической статистики», в материалах Восьмой Международной конференции IEEE по компьютерному зрению Proceedings. ICCV , Ванкувер, Британская Колумбия.
Google Scholar
Миколов, Т., Карафят, М., Бургет, Л., Черноцки, Дж., И Худанпур, С. (2010). «Языковая модель на основе рекуррентной нейронной сети», Труды 11-й ежегодной конференции Международной ассоциации речевой коммуникации , Чиба.
Google Scholar
Мисаки М., Ким Ю., Бандеттини П. А. и Кригескорте Н. (2010). Сравнение многомерных классификаторов и нормализации отклика для фМРТ с информацией о паттернах. Neuroimage 53, 103–118. DOI: 10.1016 / j.neuroimage.2010.05.051
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Мишкин М., Унгерлейдер Л. Г., Макко К. А. (1983). Объектное зрение и пространственное видение: два корковых пути. Trends Neurosci. 6, 414–417. DOI: 10.1016 / 0166-2236 (83) -x
CrossRef Полный текст | Google Scholar
Населарис, Т., Пренгер, Р. Дж., Кей, К. Н., Оливер, М., и Галлант, Дж. Л. (2009). Байесовская реконструкция естественных изображений по активности мозга человека: нейрон. Нейрон 63, 902–915. DOI: 10.1016 / j.neuron.2009.09.006
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ниделл Д., Вершинин Р. (2010). Восстановление сигнала из неполных и неточных измерений с помощью регуляризованного поиска ортогонального согласования. IEEE J. Sel. Вершина. Сигнальный процесс. 4, 310–316. DOI: 10.1109 / jstsp.2010.2042412
CrossRef Полный текст | Google Scholar
Нисимото, С., Ан, Т. В., Населарис, Т., Бенджамини, Ю., Ю., Б., и Галлант, Дж. Л. (2011). Реконструкция визуальных впечатлений от мозговой активности, вызванной естественными фильмами. Curr. Биол. 21, 1641–1646. DOI: 10.1016 / j.cub.2011.08.031
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Норман, К. А., Полин, С.М., Детре, Дж. Дж., И Хаксби, Дж. В. (2006). Помимо чтения мыслей: анализ множественных вокселей данных фМРТ. Trends Cogn. Sci. 10, 424–430. DOI: 10.1016 / j.tics.2006.07.005
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Пападимитриу А., Пассалис Н. и Тефас А. (2018). «Расшифровка общих визуальных представлений деятельности человеческого мозга с помощью машинного обучения», на Европейской конференции по компьютерному зрению, , Мюнхен, 597–606. DOI: 10.1007 / 978-3-030-11015-4_45
CrossRef Полный текст | Google Scholar
Русаковский, О., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet — задача крупномасштабного визуального распознавания. Внутр. J. Comp. Vis. 115, 211–252. DOI: 10.1007 / s11263-015-0816-y
CrossRef Полный текст | Google Scholar
Шустер М. и Паливал К. К. (1997). Двунаправленные рекуррентные нейронные сети. IEEE Trans. Сигнальный процесс. 45, 2673–2681. DOI: 10.1109 / 78.650093
CrossRef Полный текст | Google Scholar
Зенден, М., Эммерлинг, Т. К., Ван Хоф, Р., Фрост, М. А., и Гебель, Р. (2019). Реконструкция воображаемых букв из ранней зрительной коры обнаруживает тесное топографическое соответствие между визуальными мысленными образами и восприятием. Brain Struct. Функц. 224, 1167–1183. DOI: 10.1007 / s00429-019-01828-6
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ши, Н. (2015). «Отличие нисходящих эффектов от восходящих», в книге Perception and its Modalities , ред.Биггс, М. Маттен и Д. Стоукс (Oxford: Oxford University Press), 73–91.
Google Scholar
Ши, Дж., Вэнь, Х., Чжан, Ю., Хань, К., и Лю, З. (2018). Глубокая рекуррентная нейронная сеть выявляет иерархию памяти процесса во время динамического естественного зрения. Hum. Brain Mapp. 39, 2269–2282. DOI: 10.1002 / hbm.24006
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Сонг, С., Чжан, З., Лонг, З., Чжан, Дж., И Яо, Л. (2011). Сравнительное исследование методов SVM в сочетании с выбором вокселей для классификации категорий объектов на данных фМРТ. PLoS One 6: e17191. DOI: 10.1371 / journal.pone.0017191
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Соргер Б., Райтлер Дж., Дамен Б. и Гебель Р. (2012). Устройство для проверки орфографии на основе фМРТ в реальном времени, сразу обеспечивающее надежную независимую от двигателя связь. Curr. Биол. 22, 1333–1338. DOI: 10.1016 / j.cub.2012.05.022
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Spampinato, C., Palazzo, S., Kavasidis, I., Джордано, Д., Сули, Н., и Шах, М. (2017). «Глубокое обучение человеческого разума для автоматизированной визуальной классификации», в материалах конференции IEEE по компьютерному зрению и распознаванию образов , Гонолулу, Гавайи, 6809–6817.
Google Scholar
Стокс, М., Томпсон, Р., Кьюсак, Р., и Дункан, Дж. (2009). Нисходящая активация популяционных кодов определенной формы в зрительной коре во время мысленных образов. J. Neurosci. 29, 1565–1572. DOI: 10.1523 / JNEUROSCI.4657-08.2009
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Суцкевер И., Виньялс О., Ле К. В. (2014). «Последовательность для последовательного обучения с помощью нейронных сетей», в книге Advances in Neural Information Processing Systems , Сан-Франциско, Калифорния, 3104–3112.
Google Scholar
Танака, К. (1996). Нижне-височная кора и предметное зрение. Annu. Rev. Neurosci. 19, 109–139. DOI: 10.1146 / annurev.ne.19.030196.000545
CrossRef Полный текст | Google Scholar
Вэнь, Х., Ши, Дж., Чен, В., и Лю, З. (2018). Глубокая остаточная сеть предсказывает корковое представление и организацию визуальных функций для быстрой категоризации. Sci. Отчет 8: 3752. DOI: 10.1038 / s41598-018-22160-9
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Вэнь, Х., Ши, Дж., Чжан, Ю., Лу, К.-Х., Цао, Дж., И Лю, З. (2017). Нейронное кодирование и декодирование с глубоким обучением для динамического естественного зрения. Cereb. Cortex 28, 4136–4160. DOI: 10.1093 / cercor / bhx268
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Яминь, Д. Л., Хонг, Х., Кадье, К. Ф., Соломон, Э. А., Зайберт, Д., и ДиКарло, Дж. Дж. (2014). Иерархические модели с оптимизацией производительности предсказывают нейронные реакции в высших зрительных кортексах. Proc. Natl. Акад. Sci. США, 111, 8619–8624. DOI: 10.1073 / pnas.1403112111
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чжан, Х., Лю, Дж., Хубер, Д. Э., Рит, К.А., Тиан Дж. И Ли К. (2008). Обнаружение лиц на изображениях с чистым шумом: функциональное МРТ-исследование нисходящего восприятия. Нейроотчет 19, 229–233. DOI: 10.1097 / WNR.0b013e3282f49083
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Decoding Digital Talent
Например, семь из десяти стран, в которые европейские эксперты по цифровым технологиям переедут на работу, находятся в пределах этого региона; в их число входят Германия, Великобритания и Швейцария. В десятку лучших направлений работы за границей для цифровых экспертов из Латинской Америки входят США, Канада, Аргентина и Бразилия, которые довольно близки географически, и Испания, у которой есть общий язык.Точно так же половина из десяти лучших направлений для цифровых экспертов в Азиатско-Тихоокеанском регионе находится внутри региона: Австралия, Япония, Сингапур, Малайзия и Южная Корея.
Другими факторами, которые могут объяснить выбор желающих работать за границей, хотя и в пределах их родного региона, являются широкие возможности трудоустройства в соседних странах с сильной экономикой и рабочие места с компенсацией и льготами, которые конкурируют с тем, что они могли бы найти в других местах.
Лондон, лучший город в мире по количеству людей, желающих переехать, также является лучшим местом работы для цифровых экспертов.(См. Приложение 5.) Нью-Йорк занимает второе место среди желаемых рабочих мест для цифровых экспертов, равно как и среди неспециалистов. Берлин, Амстердам и Абу-Даби также привлекают немного больше экспертов в области цифровых технологий, чем неспециалистов. На основании этих выводов становится ясно, что привлекательность городов, занявших первые строчки рейтинга, превышает привлекательность их стран для людей с цифровым опытом.
Что специалисты по цифровым технологиям ценят в своей работе
Люди, которые являются экспертами в области цифровых технологий, ценят хороший баланс между работой и остальной жизнью, и они любят учиться.Из 26 важных факторов занятости, которые респонденты могли выбрать в нашем опросе, эксперты по цифровым технологиям поставили баланс между работой и личной жизнью, а также обучение и подготовку во главе своего списка. (См. Приложение 6.) За этими предпочтениями в работе тесно следуют возможности для карьерного роста и поддержания хороших отношений с коллегами.
Золтан Фузеси, внештатный поставщик ИТ-услуг и предприниматель из Будапешта, полагается на различные тренинги, чтобы поддерживать свои цифровые навыки, но он также делает это для развлечения.«Я провожу много онлайн-тренингов. Я читаю журналы. Я смотрю YouTube », — сказал Фузеси. «Я стараюсь развиваться, потому что это необходимо, и мне это нравится».
Цифровые эксперты ценят поддержание хороших отношений со своим менеджером. Они придают большее значение интересной работе, чем люди без того же уровня цифровых навыков. Кроме того, они считают, что их ценят за то, что они делают, и работу в творческой, инновационной среде среди факторов, которые они ценят больше всего.
AI и Agile Experts
В нашем опросе мы насчитали 3666 человек, которых мы называем экспертами по ИИ, то есть людей со специальными знаниями в области ИИ и способностью преподавать то, что они знают. Это число оценивает талантливых специалистов в области ИИ примерно в 14% наших респондентов-экспертов в области цифровых технологий.
Как и цифровые эксперты в целом, эксперты по искусственному интеллекту предпочитают работать в крупных компаниях.Но люди, обладающие навыками искусственного интеллекта экспертного уровня, отличаются от других цифровых экспертов по нескольким причинам. Наш анализ выявил еще больший гендерный разрыв: на мужчин приходится 72% талантов в области искусственного интеллекта, по сравнению с 68% для цифровых экспертов в целом. (См. Приложение 7.) Хотя в целом эксперты по цифровым технологиям, скорее всего, будут работать в ИТ-отраслях и технологических отраслях, специалисты по ИИ почти в равной степени представлены в ИТ и технологиях, машиностроении, промышленных товарах и производстве. Цифровые эксперты в целом считают возможности обучения и профессиональной подготовки вторым наиболее предпочтительным фактором работы; для экспертов, специализирующихся на искусственном интеллекте, эти возможности — номер один.
Семьдесят процентов людей, обладающих навыками искусственного интеллекта на уровне экспертов, готовы переехать на работу, что немного больше, чем другие эксперты в области цифровых технологий. Предпочтения экспертов в области ИИ в отношении работы за границей аналогичны предпочтениям других экспертов в области цифровых технологий. Двумя наиболее предпочтительными для них вариантами являются США (38%) и Германия (34%), при этом Нью-Йорк и Берлин являются крупными техническими центрами, которые предлагают широкие возможности трудоустройства для людей с новейшими навыками.
Некоторые рабочие факторы, которые специалисты по ИИ ценят больше всего, различаются в зависимости от места проживания — как и в случае с экспертами по цифровым технологиям в целом.Например, эксперты в области искусственного интеллекта в Северной Америке придают большое значение возможностям обучения и профессиональной подготовки, а также хорошим отношениям со своим руководителем и коллегами. Европейские эксперты в области искусственного интеллекта отдают предпочтение возможностям обучения и профессиональной подготовки, хорошему балансу между работой и личной жизнью и хорошим отношениям с коллегами. А эксперты по искусственному интеллекту в Латинской Америке придают большое значение факторам работы, которые помогают им продвигаться вперед, включая обучение и профессиональную подготовку, развитие карьеры и возможности руководить и брать на себя ответственность.
Как и ИИ, гибкость — это развивающийся навык, который определяет людей, которые могут считаться экспертами в области цифровых технологий. Согласно нашему опросу, 18% цифровых экспертов обладают экспертными знаниями в области гибких методов работы.
Agile-эксперты с большей вероятностью, чем эксперты по ИИ, будут работать в ИТ и технологических отраслях. В этих отраслях работают 20% экспертов по Agile по сравнению с 9% экспертов по ИИ. Люди с гибким опытом предпочитают работать в крупной компании. Как и эксперты в области искусственного интеллекта и эксперты по цифровым технологиям, их лучшие варианты переезда в поисках работы — это США и Германия.
Как компании, правительства и частные лица могут адаптироваться
Цифровые эксперты — популярный товар.
Для работодателей, которым нужны таланты с экспертными цифровыми навыками для ведения или расширения своего бизнеса, это означает усиление конкуренции за людей с таким цифровым опытом. Для стран это создает потребность в создании благоприятной рабочей среды, которая будет привлекать и удерживать цифровых экспертов, а также поддерживать инициативы, которые будут способствовать развитию цифровых знаний среди большего числа коренных жителей.А для самих цифровых экспертов, которые находятся в завидном положении, обладая знаниями, которые делают их востребованными работниками, это открывает возможности для карьерного роста. (См. Врезку.)
«Есть работа для меня»
Нахин Хардинес уже работал в выбранной им сфере — ИТ, — но ухватился за предложение о переводе из своей родной страны в Мексику для работы в Испании, которая является вторым по популярности местом для цифровых экспертов из Латинской Америки и шестым по привлекательности для люди с цифровыми навыками экспертного уровня по всему миру.
Хардинес получил степень компьютерного инженера и преподавал этот предмет в университете в Мексике, прежде чем устроился на работу в сфере ИТ-систем в мексиканском отделении испанского банка. Год спустя банк предложил ему переехать в Мадрид. «Я приехал, потому что в то время хотел понять испанскую культуру», — сказал Хардинес.
С тех пор он сменил работу, но все еще находится в Испании и сейчас работает старшим разработчиком и программистом в компании финансовых услуг, базирующейся в Северной Америке.
«Сейчас есть большой спрос на ИТ-технологии, но в Испании не хватает компьютерных инженеров», — сказал Хардинес. «Вот почему я все еще здесь. Потому что для меня есть работа ».
Людям, не являющимся экспертами в области цифровых технологий, необходимо найти способы развить востребованные навыки, чтобы стать более привлекательными кандидатами на работу.
Значение для компаний
Прежде чем компании что-либо предпримут, они должны понять влияние цифровых тенденций, таких как искусственный интеллект, робототехника и автоматизация, на их персонал, а также то, как повышать квалификацию нынешних сотрудников или нанимать цифровых экспертов для заполнения потенциальных пробелов.
Выявление нехватки и излишка кадровых ресурсов и создание стратегического кадрового плана для прогнозирования потребностей для выполнения конкретных должностных функций. Компании могут начать с сегментации своей нынешней рабочей силы по должностным обязанностям и исследования соответствующих новых типов должностей, для которых может потребоваться цифровой опыт.
В рамках этой работы они могут запускать моделирование предложения рабочей силы с учетом таких факторов, как коэффициент убыли. Они также могут моделировать потребности в рабочей силе, чтобы определить возможности и навыки, которые будут способствовать реализации текущих и будущих бизнес-стратегий.
Полученный план персонала может быть использован в качестве основы для HR-инициатив по заполнению пробелов посредством найма, обучения, аутсорсинга и найма внештатных сотрудников или помощников по контрактам. При необходимости его также можно использовать для сокращения излишков рабочей силы за счет сокращения штатов.
Заполните пробелы в цифровых талантах за счет повышения квалификации, переподготовки и найма. После завершения кадрового плана компании могут определить, могут ли они соответствовать требованиям к цифровым навыкам для конкретных должностей путем повышения квалификации или переподготовки нынешних сотрудников, или им необходимо нанимать сотрудников вне организации для заполнения вакансий.Программы повышения квалификации и переподготовки должны быть нацелены на превращение существующих сотрудников в цифровых экспертов, а цифровое обучение и квалификация должны быть согласованы с конкретными потребностями бизнеса. Усилия по подбору персонала должны быть сосредоточены на поиске цифровых экспертов с профилем и навыками, которые соответствуют общим стратегическим целям компании.
Использование фрилансеров и независимых подрядчиков, которых можно нанимать на временной или по мере необходимости, обеспечивает дополнительную гибкость при подборе персонала, требующем профессиональных цифровых навыков.
Независимо от окончательного конкретного плана, компании должны составить карту затрат и графиков, а также использовать средства для измерения успеха в достижении поставленных целей.
Привлекайте и удерживайте цифровых экспертов, предлагая то, что им нужно и что они ценят. Многие эксперты по цифровым технологиям не занимаются менеджментом и, возможно, не стремятся к этому. Компаниям необходимо обратиться к этому, тем не менее, ценному населению, создавая карьерные пути, не связанные с менеджментом, которые включают признание и компенсацию за другие достижения, например, обучение тому, что они знают.
Поскольку специалисты по цифровым технологиям ценят возможности обучения и подготовки больше, чем любой другой аспект работы, компании должны предлагать им множество шансов получить эти вещи, например, их назначение на краткосрочные проекты, где они могли бы поднять или улучшить цифровой навык.
Если компаниям необходимо нанимать цифровых экспертов не из существующей рабочей силы, им следует рассмотреть возможность выхода за рамки традиционных географических границ. Усилия по внешнему найму должны быть сосредоточены в первую очередь на странах, которые находятся поблизости или которые имеют общий язык или другие культурные связи, учитывая, что многие люди с цифровыми навыками решают, где им устроиться на работу, на основе этих предпочтений.
Последствия для правительств
Привлечение людей с высокими цифровыми навыками в рабочую силу увеличивает экономический успех страны и может помочь ей стать лидером в цифровом развитии. Таким образом, правительства должны предпринять шаги для создания привлекательных мест для работы, будь то в городах или целых странах. Таким образом, они могут удерживать жителей с цифровыми навыками, которые в противном случае могли бы уехать в поисках лучшей возможности в другом месте, привлекать и удерживать подобных людей из других мест и поощрять бывших жителей вернуться.
Провести общенациональный стратегический план кадровых ресурсов. Так же, как компании составляют планы кадровых ресурсов, правительства могут составлять географические планы кадровых ресурсов. Они могут начать с построения количественной модели спроса и предложения страны на цифровых экспертов. Эта модель позволит выявить пробелы и излишки цифровых талантов в данной области; анализ пробелов с использованием цифровых тенденций может показать вероятные изменения с течением времени. Результаты этого анализа могут помочь правительствам разработать стратегии, чтобы стать центром цифровых экспертов.
Закройте пробелы в цифровых талантах. Правительства могут увеличить общую численность специалистов по цифровым технологиям в своих странах, поддерживая образовательные программы, в том числе программы по обучению женщин, которые по-прежнему недопредставлены в группе специалистов с цифровыми знаниями. Возможные меры могут включать включение обучения цифровым навыкам в учебные программы на всех уровнях образования и субсидирование учебных лагерей и классов. Партнерские отношения между группами государственного и частного секторов могут дать такие решения, как университетские программы, спонсируемые частным сектором.
Создайте национальный «бренд» занятости для поддержки внутренней мобильности. Области, которые являются популярными направлениями работы для цифровых экспертов, могут воспользоваться этим положением и повысить свою привлекательность в имиджевых кампаниях, которые включают рекламу, публикации и другие формы коммуникации.
В то же время страны должны создавать пути, облегчающие иммиграцию высококвалифицированных специалистов для работы, включая программы по возвращению жителей, которые уехали на работу.
Избегайте превращения страны в страну, где «только образование». Правительствам недостаточно разработать программы по привлечению иностранных студентов к переезду для учебы в стране. Отрасли, которым нужны цифровые эксперты для процветания, рассчитывают, что эти люди останутся, когда они закончат учебу. Правительства могут поддержать их, упростив получение разрешения на работу, чтобы они могли найти работу, где они могли бы применить свои недавно приобретенные навыки.
Последствия для физических лиц
Востребованы люди с цифровым опытом.
Чтобы стать одним из таких людей, люди должны искать возможности для обучения. Они должны нестандартно мыслить как об обучении, так и о перспективах трудоустройства, в том числе о готовности переехать в другое место. Они должны принять тот факт, что, если они хотят приобрести и отточить цифровые навыки экспертного уровня, обучение будет делом всей жизни.
Развитие цифровых навыков. При соответствующей переподготовке или повышении квалификации неспециалисты могут получить навыки более высокого уровня или даже экспертного уровня — и в процессе они могут стать более привлекательными кандидатами на работу.Люди, которые могут сочетать цифровые навыки эксперта с отраслевыми знаниями, особенно привлекательны в качестве кандидатов на работу из-за широты их талантов. В то время как для приобретения некоторых цифровых навыков требуется степень, получить другие намного проще. Например, можно получить сертификат agile scrum master, не посещая школу на полный рабочий день. Люди также могут расширять свои существующие навыки в повседневной работе, например, направляя необходимое обучение к цифровым навыкам.
Будьте гибкими. Соискателям вакансий не следует ограничивать объем своего поиска. Широко распространенная оцифровка и инновации создают должности, требующие цифровых навыков не только в ИТ и инженерии, но и в таких областях, как финансы и здравоохранение. Точно так же лучшие возможности для продвижения могут существовать за пределами родины человека, если он желает сделать шаг. Для людей, которые находятся на среднем или позднем этапе своей карьеры и обладают глубоким отраслевым опытом, добавление цифровых навыков к существующей базе знаний может быть способом улучшить их перспективы в поиске работы.
Поймите, что поддержание навыков в актуальном состоянии — задача на протяжении всей карьеры. Технологии постоянно развиваются, поэтому важно продолжать учиться, чтобы быть в курсе всего нового. Людям следует направлять обучение на цифровые навыки, которые переживают резкий всплеск спроса, такие как искусственный интеллект и гибкость. Им следует использовать возможности, предоставляемые работодателями, для приобретения навыков на рабочем месте, а также использовать преимущества различных типов обучения, включая онлайн-курсы, для расширения своих знаний.
Люди с превосходными цифровыми навыками востребованы во всем мире. Наше исследование ясно показывает, что люди с цифровым опытом более охотно, чем неспециалисты, переезжают в поисках работы. Изучая эту группу, мы также теперь понимаем аспекты работы, которые они ценят больше всего, такие как обучение и тренинг, и почему они воспользуются новой возможностью. Если компании, города и страны хотят стать магнитом для цифровых экспертов, они должны действовать в соответствии с этими выводами, иначе они рискуют проиграть более быстро действующим конкурентам.
Расшифровка динамических аффективных ответов на натуралистические видео с общими нейронными паттернами
Основные моменты
- •
Предыдущие исследования извлекали аффективные нейронные репрезентации, вызывая короткие и изолированные эпизоды эмоций.
- •
Неясно, могут ли эти нейронные репрезентации улавливать динамические аффективные изменения в естественных условиях.
- •
Мы создаем нейронные классификаторы аффекта от просмотра изображений для декодирования динамических реакций во время просмотра трейлеров фильмов.
- •
Декодированные временные ряды видео коррелировали с итоговыми оценками внутри выборки и непрерывными оценками вне выборки.
- •
Результаты показывают возможность декодирования динамических ответов на натуралистический опыт с помощью предварительно обученных нейронных классификаторов.
Abstract
В этом исследовании изучалась возможность использования общих нейронных паттернов из коротких аффективных эпизодов (просмотр аффективных картинок) для декодирования расширенных динамических аффективных последовательностей в натуралистическом опыте (просмотре трейлеров к фильмам).Двадцать восемь участников просмотрели изображения из Международной системы аффективных изображений (IAPS), а в отдельном сеансе просмотрели различные трейлеры к фильмам. Сначала мы локализовали воксели в двусторонней затылочной коре (LOC), реагирующие на категории аффективных изображений, с помощью GLM-анализа, а затем выполнили гиперцентрирование между субъектами на вокселях LOC на основе их ответов во время просмотра трейлера фильма. После переназначения мы обучили классификаторы машинного обучения между предметами на аффективных изображениях и использовали классификаторы для декодирования аффективных состояний участника вне выборки как во время просмотра изображений, так и во время просмотра трейлера фильма.Внутри участников нейронные классификаторы определили категории валентности и возбуждения картинок и отслеживали валентность и возбуждение, о которых сообщали сами участники, во время просмотра видео. В совокупности нейронные классификаторы производили временные ряды валентности и возбуждения, которые отслеживали динамические рейтинги трейлеров к фильмам, полученные из отдельной выборки. Наши результаты обеспечивают дополнительную поддержку возможности использования предварительно обученных нейронных представлений для декодирования динамических аффективных реакций во время натуралистического опыта.
Рекомендуемые статьиЦитирующие статьи (0)
Просмотреть аннотацию© 2020 Авторы.Опубликовано Elsevier Inc.
Рекомендуемые статьи
Цитирующие статьи
Запись мозга, чтение мыслей и нейротехнологии: этические проблемы от бытовых устройств до декодирования речи на основе мозга
В той степени, в которой нейротехнологии каким-то образом воплощают утверждение, что разум могут быть открыты для просмотра, каждый из них поднимает этические проблемы, связанные с целым рядом вопросов, включая неприкосновенность частной жизни. С этим также связана озабоченность по поводу сведения психических состояний к наборам нейронных данных.Мы более подробно рассмотрим эти и связанные с ними области когнитивной свободы и самооценки. Прежде чем углубляться в эти функциональные проблемы, возникающие при использовании нейротехнологии, следует кое-что сказать о ее представлении.
За пределами исследовательской лаборатории на рынке уже имеется ряд BCI, включая такие продукты, как Cyberlink, Neural Impulse Actuator, Enobio, EPOC, Mindset (Gnanayutham and Good 2011). Потенциальные перспективы приложений, основанных на этих типах технологий, интересны (Mégevand 2014).Однако правдоподобность технических заявлений требует тщательной проверки.
В то время как обнаружение нейронных сигналов в принципе легко, идентифицировать их сложно (Bashashati et al. 2007). Большое количество исследовательских усилий направлено на улучшение технологии обнаружения и записи. Это должно помочь улучшить перспективы идентификации записанных нейронных сигналов. Идентификация имеет центральное значение для чтения мыслей, поскольку записанные сигналы должны каким-то образом коррелировать с психическими состояниями.Это также актуально с этической точки зрения, не в последнюю очередь из-за вероятности неверной идентификации психических состояний из-за неправильно обработанных записей мозга или из-за искажения характера происходящей записи.
Мозговые сигналы можно разделить на типы. Сайты записи можно классифицировать по функциональному признаку — например, визуальные, моторные, память, языковые области. То, что типы сигналов в определенных областях, по-видимому, «отстают» от нашей сознательной деятельности, предполагает, что деятельность должна быть классифицирована вполне объективным образом.По крайней мере, некоторые парадигмы нейротехнологического развития предполагают, что это действительно так: были сделаны заявления о таких технологиях, которые обсуждались выше, как «получение доступа к мыслям», «определение изображений по сигналам мозга», «чтение скрытых намерений» (Haynes et al. ; Кей и др., 2008). Эти утверждения предполагают, что обращение к сигналам мозга означает получение ментального содержания.
Но это может быть случай чрезмерного требования. Кажется, что требуется гораздо больше информации, чем регистрируется путем измерения сигналов мозга, если на их основе должны быть сделаны значимые выводы о содержании мысли.Например, Юкиясу Камитани провел экспериментальную работу, направленную на «расшифровку снов» по данным функциональной магнитно-резонансной томографии (фМРТ). В сообщениях СМИ эта работа была представлена так, как будто сны были просто записаны спящими участниками эксперимента (Akst 2013; Revell 2018). Но на самом деле требовалось 30–45 часов интервью на каждого участника, чтобы классифицировать небольшое количество объектов, о которых мечтали. Это впечатляющий эксперимент в области нейробиологии, но это не просто «чтение мозга» для «расшифровки сновидения».Интервью — интересное дополнение к записи сигналов мозга, потому что оно конкретно касается вербального раскрытия информации о переживании психических состояний.
Когда сообщается, что Facebook или Microsoft разработают устройство, позволяющее пользователям управлять компьютерами с помощью своего разума или своих мыслей (Forrest 2017; Solon 2017; Sulleyman 2018), это, возможно, слишком экстравагантное заявление. Хотя многие потребительские устройства продаются как «нейротехнологии», маловероятно, что они на самом деле работают, обнаруживая и записывая сигналы мозга (Wexler and Thibault, 2018).Гораздо более вероятно, что такие устройства будут реагировать на электрическую активность в мышцах лица, сигналы в которых, возможно, в 200 раз сильнее, чем в головном мозге, и гораздо ближе расположены к электродам устройства. Скорее всего, выполнение чего-то вроде набора текста с помощью такого устройства использует микродвижения, совершаемые при тщательном обдумывании слов и фраз. Мышцы, используемые при произнесении этих слов, активируются, как если бы они готовились к их произнесению, следовательно, соответствуют им таким образом, который может быть реализован в приложении для набора текста.Действительно, это заявленный режим работы устройства Google AlterEgo (Kapur et al. 2018; Whyte 2018).
Чрезмерное притязание — это этический вопрос, поскольку он может подорвать доверие к нейротехнологиям по крайней мере двумя способами: невыполнение результатов из-за искажения информации о технологиях и использование необоснованных надежд и опасений. Это основано на неверном представлении о том, как работает устройство, и о его перспективах как эффективной технологии. Это имеет этические последствия с точки зрения согласия пользователя на использование устройства.При таком искажении на работе могут иметь место различные степени обмана, которые могут повлиять на то, как мы должны рассматривать потенциальное внедрение и использование устройств, будь то участниками экспериментов или потребителями.
Опираясь на пример расшифровки сновидений, у нас есть основания полагать, что объективная регистрация сигналов мозга недостаточна для описания психического состояния именно в том смысле, что она не имеет эмпирического измерения. Мысли возникают во внутренней модели мира с определенной точки зрения.Эту модель нельзя прямо обобщить от субъекта к субъекту на основе наблюдения сигналов мозга. Можно сделать вывод только о конкретных измерениях этой модели, ограниченных с точки зрения предсказуемости, и только после большого количества тренировок в контексте строгих исследовательских условий. Объективное обещание записи сигналов мозга может быть именно тем, что отсекает их от разума, что включает в себя субъективную точку зрения.
Возможность слишком рьяного сокращения разума до некоторых нейронных данных возникает здесь как этическая проблема.«Ментальные» концепции можно обсуждать без ссылки на «нейробиологические» концепции (также наоборот). Как каждый из них может относиться к естественным видам — открытый вопрос (Churchland 1989). Поэтому следует помнить о повсеместном вопросе интерпретации, поскольку рассматривается взаимодействие между разумом и мозгом. Мысленный эксперимент с «цереброскопом» подчеркивает это.
Цереброскоп — это условное устройство, которое регистрирует всю активность всех нейронов мозга с точностью до миллисекунды.При таком полном представлении нейронной активности возникает вопрос, есть ли у нас представление о разуме. Стивен Роуз не предполагает: природа мозга как развивающейся пластичной сущности означает, что разрешение нейронной активности от миллисекунды до миллисекунды невозможно понять без полной карты генезиса этих активных нейронов и их связей:
… для того, чтобы цереброскоп мог интерпретировать конкретный паттерн нейронной активности как представление моего опыта наблюдения красной шины, ему нужно нечто большее, чем просто возможность записывать активность всех этих нейронов в настоящий момент, через несколько секунд признания и действия.Он должен быть связан с моим мозгом и телом с момента зачатия — или, по крайней мере, с рождения, чтобы иметь возможность записывать всю мою нервную и гормональную историю жизни. Тогда и только тогда он сможет расшифровать нейронную информацию. (Чоудхури и Слаби, 2016, стр. 62 и далее)
Когда речь идет о чтении мыслей, нам следует быть осторожными при рассмотрении подобных вопросов. Можно подумать, что разум сродни пространству, через которое предполагаемый читатель мыслей может пройти и исследовать то, что там можно найти.Но точка зрения Стивена Роуза предполагает более обусловленный тип разума, зависящий от его происхождения, а также состояния в определенный момент времени. Суть в том, что даже если бы один каким-то образом воспринял мысль другого, ее можно было бы понять только как субъективную мысль, а не как объективную мысль другого.
В этой связи Мекаччи и Хазелагер (2019) обсуждают некоторые философские идеи, относящиеся к конфиденциальности «ментального». Они описывают перспективность А. Дж. Айера в отношении психических состояний, отдавая приоритет конфиденциальности разума и его содержания.Такой взгляд также исключает чтение мыслей, поскольку они требуют определенной точки зрения, что означает, что они появляются не как объекты в ментальном пространстве, потенциально открытое для просмотра, а как частные содержания определенного разума.
Искажение технологии и редукционизм — каждое из них, по-видимому, имеет этическое значение само по себе. Но более подробный анализ каждого из них показывает, что они приводят к более широкому набору этических проблем в нейротехнологии. Там, где существует угроза психической конфиденциальности, может пострадать когнитивная свобода.«Когнитивная свобода» включает в себя идею о том, что человек должен быть свободен от манипуляций с мозгом, чтобы думать собственными мыслями (Sententia 2006). Эта концепция часто возникает в контексте нейро-вмешательств с точки зрения закона, психиатрии или нейроусиления (Boire 2001). Здесь это особенно заметно в связи с потенциальной потерей психической конфиденциальности.
Там, где ментальная конфиденциальность сомнительна, неясно, может ли кто-то свободно думать о себе. Там, где измерения мозговой активности могут быть выполнены (правильно или ошибочно), чтобы выявить ментальное содержание, сама нейрофизиология может рассматриваться как потенциальный информатор о самой мысли.Это должно было бы искоренить широко распространенные представления об уникальном и привилегированном доступе человека к его собственной мысли. Если увлеченный дневник узнает, что его дневник может читать другой, он может начать писать менее откровенные или разоблачающие записи. Если кто-нибудь станет уверен, что измерения его мозга могут выявить какое-либо его умственное содержимое, как он сможет воздержаться от откровенных и откровенных мыслей? Это было бы искажением нормального образа мыслей, причем довольно неприятным образом.
Эта печальная возможность ставит под угрозу и саму идею самооценки. В тех случаях, когда опасения по поводу психической неприкосновенности частной жизни приводят к подавлению познавательной свободы, нельзя быть уверенным в том, что кто-то может чувствовать себя свободным размышлять о ценностях, решениях или предложениях без угрозы последствий. Рассмотрение этически сомнительных мыслей, даже если рассматривать их только для разработки способов их опровержения, может стать опасным, если содержание мысли может быть прочитано по активности мозга.Столкнувшись с технологией, которая, кажется, читает мысли, кажется, что эта технология представляет этический риск, представляя разум как открытый для взглядов.
Часть того, что значит иметь разум и вообще быть агентом, способным действовать на основе аргументированных мнений, включает в себя рефлексию. Это может означать, что мы хотим рассмотреть то, чего мы не стали бы делать, перебираем варианты, которыми мы можем пренебречь или иным образом хотим отвергнуть. Если бы мы оказались в контексте, в котором ментальные содержания считались общедоступными, эта рефлексивная практика могла пострадать.Особенно в тех случаях, когда такие мысленные данные могут считаться более достоверными и неприукрашенными, чем те, которые приводятся в устных свидетельских показаниях. Это может основываться на принципе, о котором идет речь в приведенном выше примере «виновного знания». Эффект охлаждения сам по себе мог материализоваться из-за возможности очень интимного наблюдения с помощью записи мозга.
Посредничество мыслей, идей, размышлений в действия является частью автономной деятельности и саморепрезентации. Возможность косвенного представления таких вещей в своих действиях является частью того, что делает эти действия собственными.Если устройство для чтения мыслей можно представить как «прорезающее» посредничество для получения прямого доступа к мысленному содержанию, это не обязательно приведет к более точному представлению человека. Это также не могло служить лучшим объяснением их действий, чем объяснение, которое они могли бы предложить. В основе этого лежит конфиденциальность умственной деятельности и пространство, которое позволяет нам размышлять. Нита Фарахани назвала это «правом на познавательную свободу» (Farahany 2018).
Конфиденциальность обсуждения очень важна для предоставления места для автономии и содержания для агентства.Как уже упоминалось, внутреннюю психическую жизнь можно в большей или меньшей степени охарактеризовать с помощью поведенческих сигналов. Разница между неохотным выполнением задачи и восторженным принятием того же самого часто довольно очевидна. Но косвенная оценка чьего-либо умонастроения в их деятельности — привычная, ошибочная и устоявшаяся практика межличностного общения. Идея о том, что объективные данные могут использоваться для прямой характеристики отношения раз и навсегда, подрывает роль свободы воли.Решение действовать представляет собой сдерживание порывов, причин, желаний. Если бы было развернуто устройство для чтения мыслей, оно, безусловно, отражало бы реальное состояние ума человека. Но это может привести к тому, что действия этого человека будут более сложными, чем просто результат нейронного процесса.
Думая о примере цереброскопа, это похоже на деконтекстуализацию нейронных записей, обсуждаемую там. Природа представленных сигналов может иметь мало смысла вне биографической истории.Таким образом, они могут исказить записанное лицо. Тот факт, что обширные свидетельства сыграли такую большую роль в эксперименте по чтению сновидений, кажется, подтверждает этот мысленный экспериментальный вывод.
В более широком смысле важно обсудить цель, для которой предназначены устройства для чтения мыслей. Например, ношение гипса на сломанной руке показывает некоторые аспекты физиологического состояния человека. Однако это не вызывает особого беспокойства, потому что никто не может получить выгоду от желания «украсть» такую информацию.Но что проблематично, так это возможность неправильного использования мыслей, решений или предпочтений людей, выведенных с помощью нейротехнологий. Даже если мысли недоступны для технологии, но вполне возможно, что они так принимаются, возникают этические проблемы. С коммерциализацией нейротехнологии как технологии «чтения мыслей» эти возможности умножаются, поскольку технология может быть развернута там, где в этом нет особой необходимости. Это оставляет открытым вопрос о том, для каких целей и кем может использоваться технология.Потенциальное разнообразие технологий, участников, целей и ставок создает сложную картину.
Социально-политические последствия широко распространенной нейронной записи могут быть глубокими. На основе этих записей можно сделать подробные прогнозы относительно личных, интимных аспектов человека. Для тех, у кого есть доступ к ним, эти данные будут ценным активом. Предполагаемый интерфейс мозг-компьютер Facebook, обеспечивающий бесшовное взаимодействие пользователя с их системами, будет не только записывать и обрабатывать мозговые сигналы, но и связывать полученные из них данные с подробными сведениями о деятельности в социальных сетях (Robertson, 2019).Это будет ценным ресурсом, обеспечивающим тесную связь между явными действиями и до сих пор скрытой активностью мозга. Этот вид детального нейропрофилирования , вероятно, будет воспринят как максимально неприукрашенный и интимный, позволяющий получить представление о человеке, насколько это возможно. В той степени, в которой это верно, могут быть открыты новые измерения понимания людей через их мозг. Как и в случае с политическими скандалами с микротаргетингом с участием Facebook и Cambridge Analytica, эти данные также могут способствовать личным манипуляциям, а также нанести социальный и политический ущерб (Cadwalladr and Graham-Harrison 2018).
На личном уровне базы данных, которые связывают не только поведенческие, но и мозговые данные, представляют серьезную опасность для конфиденциальности и более широкие аспекты, связанные с достоинством. Виды профилирования, которые они позволят, могут привести к маргинализации отдельных лиц и групп, разрушая при этом солидарность между различными группами. Это произошло в преддверии Брексита на основе скрытого психометрического профилирования и нанесло длительный социальный ущерб (Collins et al., 2019; Del Vicario et al., 2017; Howard and Kollanyi, 2016).Нацеливание информации на конкретных людей или группы на основе нейронных данных станет новым фронтом в маркетинге или политической кампании, основанном на данных, что позволит использовать новые, более зловещие и, возможно, более сложные формы манипуляции (Ienca et al. 2018; Kellmeyer 2018). .
Эти примеры фокусируются на том, как можно использовать информацию для конкретных эффектов. Там, где нейропрофилирование совпадает с развитием технологий, прямые нейронные манипуляции также становятся потенциальной проблемой. Среди типов нейротехнологий, уже доступных для исследований и для потребительских целей, есть те, которые используют данные мозга для управления программным и аппаратным обеспечением, те, которые отображают данные для пользовательских целей в виде нейробиоуправления, и те, которые стремятся изменить саму мозговую активность.Эти устройства нейростимуляции или нейромодуляции используют данные, полученные из мозга, для модуляции последующей мозговой активности, регулируя ее в соответствии с некоторым желаемым состоянием (Steinert and Friedrich, 2019). Это довольно явный вызов автономии. Вне этически регулируемого контекста, такого как университетская исследовательская лаборатория, к этому нельзя относиться легкомысленно. Очевидно, что рыночных сил недостаточно для обеспечения ответственного маркетинга и использования таких потенциально мощных устройств.
Виды проблем, обсуждаемых здесь, основаны не на чтении мыслей как таковом, а скорее на эффектах, которые могут возникнуть в контексте широкого использования нейротехнологий.Однако вне рыночного контекста, в сфере текущих исследований, по крайней мере, один вид чтения мыслей может показаться технически возможным, по крайней мере, в ограниченном смысле. Проанализировав этот случай, мы сможем занять правильную позицию в отношении этических проблем, которые возникли в различных приложениях, от тех, где чтение мыслей не является центральным эффектом, до тех, в которых оно будет наиболее вероятным.
Декодирование сенсорных модальностей выявляет общие супрамодальные признаки сознательного восприятия
Значимость
Выдающаяся цель когнитивной нейробиологии — понять взаимосвязь между нейрофизиологическими процессами и сознательными переживаниями.Более или менее неявно предполагается, что общие супрамодальные процессы могут лежать в основе сознательного восприятия в различных сенсорных модальностях. Мы протестировали эту идею напрямую, используя анализ декодирования мозговой активности после околопороговой стимуляции, исследуя общие нейронные корреляты сознательного восприятия между различными сенсорными модальностями. Наши результаты по всем протестированным сенсорным модальностям выявили специфическую динамику супрамодальной мозговой сети, включая первичную сенсорную кору, не связанную с задачами.Наши результаты являются прямым доказательством общего распределенного паттерна активации, связанного с сознательным доступом в различных сенсорных модальностях.
Abstract
Все большее количество исследований выделяют общие области мозга и процессы, опосредующие сознательный сенсорный опыт. Хотя большинство исследований проводилось в визуальной модальности, неявно предполагается, что аналогичные процессы задействованы и в других сенсорных модальностях. Однако существование супрамодальных нейронных процессов, связанных с сознательным восприятием, до сих пор убедительно не доказано.Здесь мы стремимся напрямую обратиться к этой проблеме, исследуя, могут ли нейронные корреляты сознательного восприятия в одной модальности предсказать сознательное восприятие в другой модальности. В двух отдельных экспериментах мы представили участникам последовательные блоки почти пороговых задач, включающие субъективные отчеты о тактильных, визуальных или слуховых стимулах во время одного и того же захвата магнитоэнцефалографии (МЭГ). Используя анализ декодирования в постстимульный период между сенсорными модальностями, наш первый эксперимент выявил супрамодальные пространственно-временные паттерны нейронной активности, предсказывающие сознательное восприятие слабой стимуляции.Поразительно, что эти супрамодальные модели включали активность в первичных сенсорных областях, не имеющих прямого отношения к задаче (например, нейронная активность в зрительной коре головного мозга, предсказывающая сознательное восприятие слуховой стимуляции, близкой к пороговой). Мы тщательно воспроизводим наши результаты в контрольном эксперименте, который, кроме того, показывает, что соответствующие закономерности не зависят от типа сообщения (т.е. от того, было ли сообщено о сознательном восприятии при нажатии или удержании нажатия кнопки). Используя стандартные парадигмы для исследования нейронных коррелятов сознательного восприятия, наши результаты показывают общую сигнатуру сознательного доступа к сенсорным модальностям и иллюстрируют позднюю во времени и широко распространенную трансляцию нейронных репрезентаций даже в не связанные с задачами первичные сенсорные области обработки.
В то время как мозг может обрабатывать огромное количество сенсорной информации параллельно, сознательный доступ возможен только к некоторой информации, которая играет важную роль в том, как мы воспринимаем окружающую среду и действуем в ней. Таким образом, выдающейся целью когнитивной нейробиологии является понимание взаимосвязи между нейрофизиологическими процессами и сознательными переживаниями. Однако, несмотря на огромные исследовательские усилия, точная динамика мозга, которая позволяет сознательно получать доступ к определенной сенсорной информации, остается нерешенной.Тем не менее, был достигнут прогресс в исследованиях, направленных на выделение нейронных коррелятов сознательного восприятия (1), в частности, предполагающих, что сознательное восприятие — по крайней мере, если оно используется в качестве отчетности (2) — внешних стимулов в решающей степени зависит от задействования широко распределенного мозга. сеть (3). Чтобы изучить нейронные процессы, лежащие в основе сознательного восприятия, нейробиологи часто подвергают участников воздействию стимулов, близких к пороговым (NT), которые соответствуют их индивидуальным порогам восприятия (4).В экспериментах с NT существует вариативность от испытания к испытанию, при которой сознательно воспринимается около 50% стимулов с интенсивностью NT. Из-за фиксированной интенсивности физические различия между стимулами в пределах одной и той же модальности могут быть исключены как определяющий фактор, приводящий к регистрируемым ощущениям (5). Несмотря на многочисленные методы, используемые для исследования сознательного восприятия внешних событий, большинство исследований нацелено на одну сенсорную модальность. Однако любой конкретный нейронный паттерн, идентифицированный как коррелят сознания, требует доказательств того, что он в некоторой степени обобщает, например.g., через сенсорные модальности. Мы утверждаем, что это пока убедительно не показано.
В визуальной области было показано, что сознательный опыт, подлежащий отчету, присутствует, когда первичная зрительная корковая активность распространяется на иерархически расположенные ниже по течению области мозга (6), требуя активации лобно-теменных областей для полной отчетности (7). Тем не менее, недавнее исследование магнитоэнцефалографии (МЭГ) с использованием задачи визуальной маскировки выявило раннюю активность первичной зрительной коры как лучший предиктор сознательного восприятия (8).Другие исследования показали, что нейронные корреляты слухового сознания связаны с активацией лобно-височных, а не лобно-теменных сетей (9, 10). Кроме того, повторяющаяся обработка данных между первичной, вторичной соматосенсорной и премоторной корой была предложена как потенциальные нейронные сигнатуры тактильного сознательного восприятия (11, 12). В самом деле, повторяющаяся обработка данных между областями коры высшего и низшего порядка внутри определенной сенсорной системы считается маркером сознательной обработки (6, 13, 14).Более того, альтернативные теории, такие как концепция глобального рабочего пространства (15), расширенная Dehaene et al. (16) постулируют, что лобно-теменное взаимодействие помогает «транслировать» релевантную информацию по всему мозгу, делая ее доступной для различных когнитивных модулей. В различных электрофизиологических экспериментах было показано, что этот процесс происходит относительно поздно (~ 300 мс) и может быть связан с повышенной вызванной активностью мозга после появления стимула, такого как так называемый сигнал P300 (17⇓ – 19). Такая поздняя активность мозга, кажется, коррелирует с перцептивным сознанием и может отражать глобальную трансляцию интегрированного стимула, делающего его сознательным.Взятые вместе, теории и экспериментальные данные свидетельствуют в пользу различных «сигнатур» сознания от повторяющейся активности в сенсорных областях до глобальной трансляции информации с вовлечением лобно-теменных областей. Хотя это обычно подразумевается, до сих пор неясно, связаны ли похожие пространственно-временные паттерны нейронной активности с сознательным доступом к различным сенсорным модальностям.
В текущем исследовании мы исследовали сознательное восприятие в различных сенсорных системах, используя многомерный анализ данных МЭГ.Наше рабочее предположение состоит в том, что активность мозга, связанная с сознательным доступом, должна быть независимой от сенсорной модальности; то есть нейронные процессы, связанные с надмодальным сознанием, должны демонстрировать пространственно-временное обобщение. Такую гипотезу лучше всего проверить, применяя методы декодирования к электрофизиологическим сигналам, записанным при исследовании сознательного доступа в различных сенсорных модальностях. Применение многомерного анализа паттернов (MVPA) к электроэнцефалографии (ЭЭГ) и измерениям МЭГ обеспечивает повышенную чувствительность при обнаружении экспериментальных эффектов, распределенных в пространстве и времени (20–23).MVPA часто используется в сочетании с методом прожектора (24, 25), который включает в себя перемещение небольшого пространственного окна по данным для выявления областей, содержащих декодируемую информацию. Комбинация обоих методов обеспечивает пространственно-временное обнаружение оптимальной декодируемости, определяя, где, когда и как долго определенный паттерн присутствует в активности мозга. Такой многомерный анализ декодирования был предложен в качестве альтернативы в исследованиях сознания, дополняя другие традиционные одномерные подходы к идентификации нейронной активности, прогнозирующей сознательный опыт на уровне одного исследования (26).
Здесь мы получили данные МЭГ, в то время как каждый участник выполнял три различных стандартных задачи NT на трех сенсорных модальностях с целью характеристики супрамодальных мозговых механизмов сознательного восприятия. В первом эксперименте мы показываем, как нейронные паттерны, связанные с перцептивным сознанием, могут быть обобщены в пространстве и времени внутри и, что наиболее важно, между различными сенсорными системами, с помощью классификационного анализа восстановленной мозговой активности на уровне источника. В дополнительном контрольном эксперименте мы воспроизводим основные результаты и исключаем возможность того, что наблюдаемые нами закономерности связаны с подготовкой / выбором ответа, несмотря на необходимость сообщать об обнаружении стимулов в каждом испытании в наших экспериментах.
Результаты
Поведение.
Мы исследовали частоту обнаружения участниками NT, фиктивного (отсутствие стимуляции) и улова (интенсивность стимуляции выше порога восприятия) отдельно для начального и контрольного экспериментов. Для контроля ложных тревог и корректировки показателей отклонения в ходе эксперимента использовались пробные и фиктивные испытания.
Во время начального эксперимента участникам приходилось ждать экрана ответа и нажимать кнопку в каждом испытании, чтобы сообщить о своем восприятии (рис.1 А ). Однако во время контрольного эксперимента для управления картированием моторной реакции использовался специальный экран ответа. В каждом испытании участники должны использовать различное отображение ответов в зависимости от цвета круга вокруг вопросительного знака во время экрана ответов (рис. 1 C ).
Рис. 1.Планы экспериментов и поведенческие результаты. ( A и B ) Первоначальный эксперимент. ( C и D ) Контрольный эксперимент. ( A ) После переменного интервала между испытаниями между 1.3 и 1,8 с, в течение которых участники фиксировались на центральной белой точке, тактильный / слуховой / визуальный стимул (в зависимости от пробега) предъявлялся в течение 50 мс с индивидуальной интенсивностью восприятия. Через 500 мс после предъявления стимула на экране появлялся вопросительный знак, и участники указывали свое восприятие, нажимая одну из двух кнопок (т.е. стимуляция «присутствовала» или «отсутствовала») правой рукой. ( B и D ) Средние групповые уровни обнаружения стимуляции NT составляли около 50% при различных сенсорных модальностях.Фальшивые испытания, отмеченные белым (без стимуляции), и испытания по отлову, отмеченные черным (высокоинтенсивная стимуляция), значительно отличались от состояния NT, выделенного серым, в рамках одной и той же сенсорной модальности для обоих экспериментов. Планки погрешностей отображают SD. ( C ) В контрольном эксперименте использовали идентичные временные параметры; однако для управления картированием двигательной реакции использовался специальный дизайн экрана ответа. В каждом испытании участники должны использовать разное отображение ответов в зависимости от цвета круга вокруг вопросительного знака на экране ответов.Два цвета (синий или желтый) использовались и отображались случайным образом во время контрольного эксперимента. Один цвет был связан с правилом отображения ответа «нажимайте кнопку, только если есть стимуляция» (для обнаруженного состояния, близкого к пороговому), а другой цвет был связан с противоположным отображением ответа: «нажимайте кнопку, только если стимуляция отсутствует. »(Для необнаруженных околопороговых условий). Связь между отображением одного ответа и определенным цветом (синим или желтым) была фиксированной для одного участника, но была предопределена случайным образом для разных участников.
Для первоначального эксперимента и для всех участников ( n = 16), уровни обнаружения для экспериментальных испытаний NT составляли 50% (SD: 11%) для слуховых пробежек, 56% (SD: 12%) для визуальных пробежек и 55% (стандартное отклонение: 8%) для тактильных пробежек. Частота обнаружения для проб по уловам составляла 92% (SD: 11%) для слуховых пробежек, 90% (SD: 12%) для визуальных пробежек и 96% (SD: 5%) для тактильных пробежек. Средняя частота ложных тревог в мнимых испытаниях составляла 4% (SD: 4%) для слуховых пробежек, 4% (SD: 4%) для визуальных пробежек и 4% (SD: 7%) для тактильных пробежек (рис.1 В ). Частота обнаружения экспериментальных испытаний NT во всех сенсорных модальностях значительно отличалась от таковых при испытаниях улова (слуховой, T 15 = -14,44, P <0,001; визуальный, T 15 = -9,47, P <0,001; тактильные, T 15 = -20,16, P <0,001) или фиктивные испытания (слуховые, T 15 = 14,66, P <0,001; визуальные, T 15 = 16,99, P <0,001; тактильно, Т 15 = 20.66, P <0,001).
Подобные результаты наблюдались для контрольного эксперимента у всех участников ( n = 14). Частота обнаружения для экспериментальных испытаний NT составляла 52% (SD: 17%) для слуховых пробежек, 43% (SD: 17%) для визуальных пробежек и 42% (SD: 12%) для тактильных пробежек. Частота обнаружения при испытаниях по улову составляла 97% (СО: 2%) для слуховых пробежек, 95% (СО: 5%) для визуальных пробежек и 95% (СО: 4%) для тактильных пробежек. Средняя частота ложных тревог в мнимых испытаниях составляла 11% (SD: 4%) для слуховых пробежек, 7% (SD: 6%) для визуальных пробежек и 7% (SD: 6%) для тактильных пробежек (рис.1 В ). Показатели обнаружения экспериментальных испытаний NT во всех сенсорных модальностях значительно отличались от таковых при испытаниях на улов (слуховой, T 13 = -9,64, P <0,001; визуальный, T 13 = -10,78, P <0,001; тактильные, T 13 = -14,75, P <0,001) или мнимые испытания (слуховые, T 13 = 7,85, P <0,001; визуальные, T 13 = 6,24, P <0,001; тактильно, Т 13 = 9.75, P <0,001). В целом поведенческие результаты сопоставимы с результатами других исследований (27, 28). Время индивидуальной реакции и характеристики указаны в приложении SI , таблица S2.
Событийная нейронная активность.
Чтобы сравнить постстимульную обработку для «обнаруженных» и «необнаруженных» испытаний, вызванные ответы были рассчитаны на уровне источника для начального эксперимента. Как общая закономерность для всех сенсорных модальностей, поля, связанные с событиями на уровне источника (ERF), усредненные по всем источникам мозга, показывают, что стимулы, зарегистрированные как обнаруженные, приводили к выраженной постстимульной нейронной активности, тогда как незарегистрированные стимулы — нет (рис.2 А ). Подобные общие закономерности наблюдались для контрольного эксперимента с идентичным одномерным анализом ( SI Приложение , рис. S2). ERF значительно различались в течение усредненного времени со специфичностью, зависящей от сенсорной модальности, нацеленной на стимуляцию. Слуховые стимулы, о которых сообщалось, выявляют значительные различия по сравнению с необнаруженными испытаниями сначала между 190 и 210 мс, затем между 250 и 425 мс и, наконец, между 460 и 500 мс после появления стимула (рис.2 A , Левый ). Визуальная стимуляция, о которой сообщалось, как обнаруженная, вызывает большое увеличение амплитуды ERF по сравнению с необнаруженными испытаниями с 230 до 250 мс и от 310 до 500 мс после начала стимула (рис. 2 A , Средний ). Тактильная стимуляция, о которой сообщалось, как обнаруженная, вызывает раннее увеличение амплитуды ERF между 95 и 150 мс, а затем более позднюю активацию между 190 и 425 мс после начала стимула (рис. 2 A , справа ). В нашем протоколе такое раннее различие ERF для испытаний тактильной NT может быть связано с экспериментальной установкой, в которой стимуляция слуховых и зрительных целей возникла из фоновой стимуляции (постоянный белый шум и отображение на экране), тогда как тактильные стимулы остаются изолированными временными сенсорными целями (материалы ). и методы ).
Рис. 2.NT исследует связанные с событиями реакции для различных сенсорных модальностей: слуховых ( слева, ), зрительных (, центр, ) и тактильных (, справа, ). ( A ) Абсолютное значение на уровне источника (базовая линия, скорректированная для целей визуализации) среднего, связанного с групповым событием (сплошная линия) и SEM (заштрихованная область) в обнаруженном (красный) и необнаруженном (синий) состоянии для всех источников мозга . Значимые временные окна отмечены нижними сплошными линиями (черная линия: P с поправкой Бонферрони <0.05) для сравнения обнаруженных и необнаруженных испытаний. Карты относительной локализации источников представлены в B для усредненного периода времени. ( B ) Исходная реконструкция значимого периода времени, отмеченного в A для контраста обнаруженных и необнаруженных испытаний, замаскированная на P с кластерной коррекцией <0,05.
Локализация источника этих конкретных интересующих периодов времени была выполнена для каждой модальности (рис. 2 B ).Слуховое состояние демонстрирует значительную раннюю активность источника, в основном локализованную в двусторонней слуховой корке, верхней височной борозде и правой нижней лобной извилине, тогда как поздний значимый компонент в основном локализован в правой височной извилине, двусторонней прецентральной извилине и левой нижней и средней лобной извилине. Наблюдается большая активизация визуальных условий, включая первичные визуальные области; веретеновидная и известковая борозда; и активация большой лобно-теменной сети, включая двустороннюю нижнюю лобную извилину, нижнюю теменную борозду и поясную кору.Ранний контраст тактильной вызванной реакции показывает большое различие в активации мозга, включая первичные и вторичные соматосенсорные области, но также большое участие правой лобной активности. Поздний контраст тактильной вызванной реакции представляет активацию мозга, включая левую лобную извилину, левую нижнюю теменную извилину, двустороннюю височную извилину и дополнительную двигательную зону.
Различия во времени между обнаруженными и необнаруженными стимулами наиболее четко проявляются через 150-200 мс (см. Топографии в приложении SI , рис.S5). Это отличается при сравнении уловов и фиктивных испытаний, где можно наблюдать ранние различия (т. Е. До 150 мс) ( SI Приложение , рис. S1 и S5). Разница в задержке между обработкой тактильной стимуляции и другими модальностями менее выражена для этого состояния, когда цель явно присутствует или отсутствует. На сенсорном уровне для всех сенсорных модальностей различия начинаются относительно очаговыми ( SI Приложение , рис. S5) в предположительно сенсорных областях обработки и со временем становятся все более широко распространенными.Эти вызванные позже эффекты реакции описательно подобны тем, которые наблюдаются для стимулов, близких к пороговым, что подчеркивает их предполагаемую значимость для обеспечения сознательного доступа.
Декодирование и многомерный поисковый анализ по времени и по областям мозга.
Мы исследовали обобщение активации мозга во времени внутри и между различными сенсорными модальностями. С этой целью мы провели многомерный анализ восстановленной активности мозга на уровне источника из первоначального эксперимента.Обобщающий анализ времени, представленный в виде временной матрицы между 0 и 500 мс после начала стимула, показывает значительную точность декодирования для каждого условия (рис. 3 A ). Мы обучаем и тестируем наши классификаторы на 50% набора данных с одинаковой долей испытаний, исходящих из каждого отдельного цикла сбора данных, с компенсацией потенциальной усталости или эффекта привыкания в ходе экспериментов. Как видно на черных ячейках, расположенных по диагонали на рис. 3 A , перекрестное проверочное декодирование выполнялось в рамках той же сенсорной модальности.Однако недиагональные эритроциты на фиг. 3 A представляют анализ декодирования между различными сенсорными модальностями. Внутри каждой ячейки данные, представленные по диагонали (пунктирная линия), показывают среднюю точность классификаторов для определенного момента времени, используемого для процедуры обучения и тестирования, тогда как недиагональные данные показывают потенциальную способность классификатора обобщать декодирование на основе другого обучения и тестирования. процедура по временным точкам. Действительно, мы наблюдали способность одного и того же классификатора, обученного в конкретный момент времени, обобщать свою производительность декодирования на несколько временных точек (см. Внедиагональное значимое декодирование внутри каждой ячейки на рис.3 А ). Чтобы оценить этот результат, мы вычислили среднюю продолжительность значимого декодирования в моменты времени тестирования на основе различных моментов времени обучения (рис. 3 B ). В среднем, декодирование в рамках одной и той же модальности, обобщение классификатора начинается через 200 мс, и мы наблюдали значительную максимальную точность классификации через 400 мс (рис. 3 B , Top ).
Рис. 3.Повременный обобщающий анализ внутри и между сенсорными модальностями (для испытаний NT).Матрицы 3 × 3 результатов декодирования представлены во времени (от начала стимуляции до 500 мс после). ( A ) В каждой ячейке представлен результат MVPA прожектора с повременным обобщающим анализом, где точность классификатора была значительно выше вероятности (50%) (замаскировано на P исправлено <0,005). Для каждой матрицы временного обобщения классификатор был обучен в определенной временной выборке (вертикальная ось: время обучения) и протестирован на всех временных выборках (горизонтальная ось: время тестирования).Черная пунктирная линия соответствует диагонали матрицы временного обобщения, то есть классификатору, обученному и протестированному на одной временной выборке. Эта процедура применялась для каждой комбинации сенсорной модальности; то есть, представленный в строке Верхний представляет собой анализ декодирования, выполненный классификаторами, обученными слуховой модальности и протестированными на слуховой, визуальной и тактильной ( левый , центральный и правый столбцы, соответственно) для двух классов: обнаруженные и необнаруженные испытания.Ячейки, очерченные осями черных линий (на диагонали), соответствуют декодированию одной и той же сенсорной модальности, тогда как клетки, очерченные осями красных линий, соответствуют декодированию различных модальностей. ( B ) Сводная информация о средней производительности обобщения по времени и декодирования с течением времени для всех анализов внутри модальности ( верхний : среднее значение на основе трех черных ячеек A ) и межмодального анализа ( низ : среднее на основе шести эритроцитов A ).Для каждой конкретной временной точки обучения по оси x вычислялась средняя продолжительность способности классификатора значительно обобщать моменты времени тестирования и отражалась по оси y . Кроме того, нормализованные средние значения достоверности классификаторов за все время тестирования для определенного момента времени обучения представлены в виде градиента цветовой шкалы.
Ранние различия, характерные для тактильной модальности, были уловлены классификационным анализом, показывая значительную точность декодирования уже через 100 мс без сильного обобщения времени для этой сенсорной модальности, тогда как слуховые и зрительные условия показывают значительное декодирование, начинающееся только через 250-300 мс после появление стимула.Такая ранняя динамика, специфичная для тактильной модальности, могла бы объяснить недиагональную точность для всех межмодальностей декодирования, в которых задействована тактильная модальность (рис. 3 A ). Интересно, что анализ временного обобщения, касающийся декодирования межсенсорных модальностей (эритроциты на рис. 3 A ), выявил значительную максимальную генерализацию около 400 мс (рис. 3 B , Bottom ). В целом, анализ с обобщением по времени выявил временные кластеры, ограниченные поздней активностью мозга с максимальной точностью декодирования в среднем через 300 мс для всех условий.Сходство этого временного кластера по всем трем сенсорным модальностям предполагает универсальность такой активации мозга.
Ограниченные соответствующими значимыми временными кластерами (рис. 3 A ), мы исследовали основные источники мозга, полученные в результате анализа прожектором внутри и между условиями (рис. 4). Декодирование в рамках той же сенсорной модальности показало более высокую достоверную точность в соответствующей сенсорной коре для каждого конкретного состояния модальности (рис. 4, графики мозга по диагонали).Кроме того, декодирование с помощью прожектора слуховой модальности выявило также сильное вовлечение зрительной коры (рис.4, верхний ряд и левый столбец ), тогда как декодирование соматосенсорной модальности выявило вовлечение теменных областей, таких как предклинье (рис.4, низ ). ряд и правый столбец ). Однако анализ декодирования прожектором между различными сенсорными модальностями выявил более высокую точность декодирования в лобно-теменных областях мозга в дополнение к различным первичным сенсорным областям (рис.4, графики мозга вне диагонали).
Рис. 4.Пространственное распределение значимых прожекторов, декодирующих MVPA внутри и между сенсорными модальностями. Показаны исходные карты головного мозга для средней точности декодирования, ограниченной связанным с временным обобщением значимым по времени кластером (см. Рис. 3 A ). Карты мозга были пороговыми, показывая только 10% максимальной достоверной точности декодирования для каждого соответствующего кластера по времени. Очертание черной линией отделяет все карты мозга декодирования между сенсорными модальностями от перекрестной проверки в рамках одного анализа декодирования сенсорных модальностей по диагонали.
Декодирование и многомерный прожекторный анализ по всем сенсорным модальностям.
Мы дополнительно исследовали возможность декодирования обобщенных паттернов активности мозга по всем сенсорным модальностям в одном анализе путем декодирования обнаруженных и необнаруженных испытаний по всем блокам вместе (рис. 5 A ). Первоначально мы выполнили этот конкретный анализ с данными из первого эксперимента и отдельно с данными из контрольного эксперимента, чтобы воспроизвести наши результаты и контроль потенциальной смещения моторной реакции ( SI Приложение , рис.S3). Откладывая отображение ответа до момента после предъявления стимула случайным образом во время контрольного эксперимента, нейронные паттерны во время соответствующих периодов предположительно не могут быть искажены выбором / подготовкой ответа. Важно отметить, что анализ, проведенный в контрольном эксперименте, использовал идентичные данные в приложении SI , рис. S3 B и C , но только назначение испытаний (т. Е. Два класса определения) для декодирования было различным: «обнаружено и не обнаружено» ( SI Приложение , рис.S3 B ) или «ответ против отсутствия ответа» ( SI Приложение , рис. S3 C ). Только декодирование сознательного отчета (то есть обнаруженного в сравнении с необнаруженным) показало значимые по времени кластеры ( SI Приложение , рис. S3 A и B ). Этот результат исключает мешающее влияние моторного отчета и снова убедительно свидетельствует о существовании общего супрамодального паттерна, связанного с сознательным восприятием.
Рис. 5.Повременное обобщение и анализ декодирования прожектором мозга по всем сенсорным модальностям (для испытаний NT).Показаны обобщенные результаты как для начального, так и для контрольного экспериментов. ( A ) Результаты декодирования представлены во времени (от начала стимуляции до 500 мс после). Показан результат MVPA прожектора с временным обобщающим анализом «обнаруженных» и «необнаруженных» испытаний по всем сенсорным модальностям. На графике показаны временные кластеры, где точность классификатора была значительно выше вероятности (50%) (замаскировано на P исправлено <0,005). Черная пунктирная линия соответствует диагонали матрицы временного обобщения, т.е.е., классификатор, обученный и протестированный на одной временной выборке. Горизонтальные черные линии разделяют временные окна (W1, W2 и W3) ( B ) Сводка среднего временного обобщения и производительности декодирования с течением времени ( A ). Для каждой конкретной временной точки обучения по оси x вычислялась средняя продолжительность способности классификатора значительно обобщать моменты времени тестирования и отражалась по оси y . Кроме того, нормализованные средние значения достоверности классификаторов за все время тестирования для определенного момента времени обучения представлены в виде градиента цветовой шкалы.На основе этого резюме были изображены три временных окна для изучения пространственного распределения декодирования прожектором (W1, [0–250] мс; W2, [250–350] мс; W3, [350–500] мс). ( C ) Пространственное распределение MVPA-декодирования значимого прожектора для значимых временных кластеров, изображенных в A и B . Для карт мозга был установлен порог, показывающий только 10% максимально значимой ( P скорректированной <0,005) точности декодирования для каждого соответствующего кластера по времени.
Мы исследовали сходство результатов временного обобщения путем объединения данных из обоих экспериментов (рис. 5 A ). Мы проверили значительную временную динамику паттернов мозговой активности по всем нашим данным, принимая во внимание, что менее стабильные или похожие паттерны не выдерживают групповой статистики. В целом, способность одного классификатора к обобщению во времени, кажется, линейно увеличивается после критического момента времени около 100 мс. Мы показываем, что в то время как ранние паттерны (<250 мс) довольно недолговечны, временная обобщаемость увеличивается, показывая значения стабильности после ~ 350 мс (рис.5 В ). Чтобы проследить за потенциальными генераторами, лежащими в основе этих временных паттернов, мы изобразили результаты прожектора из трех конкретных временных окон (W1, W2 и W3), касающиеся декодирования временного обобщения и распределения нормализованной точности во времени (рис. 5 C ). W1 от начала стимуляции до 250 мс отображает первое существенное декодирование прожектором, обнаруженное в этом анализе, W2 от 250 до 350 мс отображает первый период обобщения, когда точность декодирования низка, и, наконец, W3 от 350 до 500 мс представляет второй период обобщения по времени. где была обнаружена более высокая точность декодирования (рис.5 В ). Изображение результатов выделяет предклинье, островок, переднюю часть поясной извилины, а также лобные и теменные области, в основном задействованные в течение первого значимого временного окна (W1), в то время как главный значительный кластер второго временного окна (W2) расположен над левым прецентральным моторным кортикальным слоем. Интересно, что окно позднего времени (W3) показывает более сильное декодирование по сравнению с первичной сенсорной корой, где точность наиболее высока: язычная и калькариновая борозда, верхняя височная извилина и извилина Хешля, а также правая постцентральная извилина (рис.5 С ). Источники, представленные при анализе прожектором, предполагают сильное совпадение с функциональными сетями мозга, связанными с обнаружением внимания и значимости (29), особенно в самые ранние периоды времени (W1 и W2) ( SI Приложение , рис. S4).
Обсуждение
Для того, чтобы нейронный процесс был сильным соперником в качестве нейронного коррелята сознания, он должен иметь некоторое обобщение, например, по сенсорным модальностям. Это — несмотря на неявное предположение — никогда напрямую не проверялось.Чтобы решить эту важную проблему, мы исследовали стандартный эксперимент NT, нацеленный на три различных сенсорных модальности, чтобы изучить общую пространственно-временную активность мозга, связанную с сознательным восприятием, с использованием многомерного анализа и анализа прожектором. Наши результаты и выводы во многом зависят от актуальности задачи «парадигм, основанных на отчетах», в отличие от «парадигм отсутствия отчетов» (30). Участники выполнили задачу по обнаружению и сообщили о своем восприятии для каждого испытания. Было показано, что такие протоколы могут вызывать дополнительные поздние (после 300 мс) компоненты активности мозга по сравнению с другими парадигмами (31).Наши результаты, касающиеся реакций, вызванных постстимулом, согласуются с предыдущими исследованиями для каждой конкретной сенсорной модальности, показывая более сильную активацию мозга, когда стимуляция считалась воспринимаемой (27, 28, 32). Важно отметить, что, используя преимущества декодирования, мы предоставляем прямые доказательства общих электрофизиологических коррелятов сознательного доступа через сенсорные модальности.
ERF Различия во времени в зависимости от сенсорных модальностей.
Наши первые результаты предполагают значительные временные и пространственные различия, когда для исследования сенсорно-специфических вызванных реакций использовался одномерный контраст между обнаруженными и необнаруженными испытаниями.На уровне источника глобальная средняя активность группы выявила различные значимые периоды времени в соответствии с целевой сенсорной модальностью, где можно наблюдать модуляции вызванных ответов, связанных с обнаруженными испытаниями (рис. 2 A ). В слуховой и зрительной модальностях мы обнаружили в основном значимые различия через 200 мс. В слуховой области устойчивые реакции, модулируемые восприятием и вниманием, примерно через 200 мс от начала звука, были обнаружены в двусторонней слуховой и лобной областях с использованием МЭГ (33, 34).Предыдущее исследование с использованием MEG подтвердило эффекты, связанные с осознанием, через 240-500 мс после целевой презентации во время визуальной презентации (35).
Наши результаты показывают ранние различия в переходных ответах (для обнаруженного контраста по сравнению с необнаруженным) для соматосенсорной области по сравнению с другими сенсорными модальностями и были ранее идентифицированы с помощью ЭЭГ примерно через 100 и 200 мс (36). Более того, предыдущие исследования МЭГ показали, что ранняя модуляция амплитуды сигнала мозга (<200 мс) связана с тактильным восприятием в задачах NT (28, 37, 38).Такие различия менее выражены в отношении контраста между попытками улова и фиктивными испытаниями по сенсорным модальностям ( SI Приложение , рис. S1). Раннее различие ERF для испытаний тактильной NT может быть связано с экспериментальной установкой, в которой стимуляция слуховых и зрительных целей возникла из фоновой стимуляции (постоянный белый шум и отображение на экране), тогда как тактильные стимулы остаются изолированными временными сенсорными целями. Несмотря на эти различия, анализ обобщения во времени смог уловить сходную активность мозга, происходящую в разных временных масштабах в этих трех сенсорных модальностях.
Локализация источников, выполненная с одномерными контрастами для каждой сенсорной модальности, предполагает различия в активации сети с некоторым вовлечением схожих областей мозга в поздних временных окнах, таких как нижняя лобная извилина, нижняя теменная извилина и дополнительная моторная область. Однако качественно похожие топографические закономерности, наблюдаемые при таком анализе, нельзя однозначно интерпретировать как аналогичные процессы в мозге. Важный вопрос заключается в том, можно ли использовать эти паттерны нейронной активности в рамках определенной сенсорной модальности для декодирования субъективного отчета о стимуляции в другом сенсорном контексте.Многовариантный анализ декодирования, который мы провели в следующем анализе, был направлен на ответ на этот вопрос.
Идентификация общей активности мозга через сенсорные модальности.
Анализ многомерного декодирования использовался для уточнения пространственно-временного сходства этих различных сенсорных систем. В целом, стабильные характеристики сигналов мозга были предложены как временная стабилизация распределенных корковых сетей, участвующих в сознательном восприятии (39). Используя точное временное разрешение сигнала МЭГ и анализ обобщения во времени, мы исследовали стабильность и временную динамику мозговой активности, связанной с сознательным восприятием через сенсорные системы.В дополнение к временному анализу в этом исследовании мы также использовали анализ на уровне источника как указание на возможное происхождение эффектов в мозге. Присутствие сходной мозговой активности может быть выявлено между модальностями с использованием такой техники, даже если значительная модуляция ERF распределяется во времени. Как и ожидалось, анализ обобщения времени между модальностями, включающий тактильные прогоны, показывает недиагональное значимое декодирование из-за ранней значительной активности мозга для тактильной модальности (рис.3 А ). Этот результат предполагает существование ранних, но схожих паттернов мозговой активности, связанных с сознательным восприятием в тактильной области по сравнению со слуховой и зрительной модальностями.
Как правило, результаты декодирования выявили значительный временной кластер, начинающийся около 300 мс, с высокой точностью классификатора, что говорит в пользу поздней нейронной реакции, связанной с сознательным отчетом. Фактически, мы наблюдали способность одного и того же классификатора, обученного в определенные моменты времени с определенным условием сенсорной модальности, обобщать свои характеристики декодирования по нескольким временным точкам с той же или другой сенсорной модальностью.Этот результат говорит в пользу надрамодальных паттернов мозговой активности, которые стабильны и стабильны во времени. Кроме того, анализ прожектором по областям мозга дает попытку изобразить активацию сети мозга во время этих значительных кластеров обобщения времени. Обратите внимание, что, как видно из множества других исследований с использованием декодирования (22, 23, 40, 41), средняя точность может быть относительно низкой, но все же остается значительной на уровне группы. Обратите внимание, однако, что в отличие от многих других когнитивных нейробиологических исследований, использующих декодирование (41, 42), мы не применяем практику «субсредних» испытаний для создания «псевдо» одиночных испытаний, что естественным образом повышает среднюю точность декодирования (43).Кроме того, статистическая строгость нашего подхода подчеркивается тем фактом, что представленные результаты декодирования ограничиваются очень значимыми эффектами ( P исправлено <0,005; Материалы и методы ). Важно то, что мы воспроизвели наши результаты — применяя идентичные очень консервативные статистические пороги — во втором контрольном эксперименте, глядя на контраст отчета о сознательном восприятии независимо от активности двигательной реакции ( SI Приложение , рис.S3). Наши результаты согласуются с результатами предыдущих исследований в обосновании важности поздних паттернов активности как важнейших маркеров сознательного доступа (7, 44) и процессов принятия решений (10, 45).
Из-за настроек нашего протокола с небольшим количеством «ловушек» и «фиктивных» испытаний, мы решили сконцентрировать наш анализ на контрасте стимулов, близких к пороговым (обнаруженные и необнаруженные). Однако остаются интересные вопросы относительно обработки необнаруженных целей по сравнению с отсутствием стимулов.В будущих экспериментах следует исследовать такие вопросы, уравновешивая количество фиктивных испытаний («цель отсутствует») и испытаний, близких к пороговым, чтобы исследовать точную обработку необнаруженных целей в различных модальностях с использованием техник декодирования, аналогичных тем, которые представлены в этом эксперименте.
Кроме того, в этом исследовании мы исследовали области мозга, лежащие в основе временной динамики сознательного отчета, используя декодирование прожектором источника мозга. Зная ограничения такого анализа MEG и используя пространственно грубое разрешение сетки для вычислительной эффективности (3 см), мы ограничили отображение результатов основной максимальной точностью декодирования 10% по всем областям мозга прожектора.Некоторые из областей мозга, обнаруженные в нашем анализе прожектором, а именно глубокие структуры мозга, такие как островок и передняя поясная кора, являются общими с другими функциональными сетями мозга, такими как сеть значимости (46, 47). Также ранее было обнаружено, что верхняя и теменная кора головного мозга активируются требующими внимания когнитивными задачами (48). Следовательно, мы подчеркиваем, что из нашего исследования нельзя сделать вывод, что наблюдаемая сеть, обозначенная на рис. 5 C , предназначена исключительно для сознательного сообщения.В самом деле, декодирование с помощью ловли и мнимых испытаний также может вызывать схожую модель временного декодирования между модальностями по сравнению с анализом околопороговой стимуляции, говоря в пользу аналогичного зажигания общей сети при нормальном восприятии высококонтрастных стимулов для трех сенсорных модальностей. цель нашего эксперимента ( SI Приложение , рис. S6). Даже если этот дополнительный анализ должен быть предпринят с осторожностью из-за небольшого количества испытаний для этих состояний в нашем протоколе ( SI Приложение , Таблица S1), он информативен в отношении участия обычных сетей мозга, обрабатывающих восприятие, в нашей задаче. .Фактически, мозговые сети, идентифицированные в этом исследовании, имеют общие области мозга и динамику с сетями внимания и значимости, которые остаются соответствующими механизмами для выполнения задачи NT. Интересно, что эта часть сети, по-видимому, более задействована во время начальной части процесса, до вовлечения моторных областей мозга (Fig. 5 C и SI Приложение , Fig. S4).
Некоторые области мозга, участвующие в моторном планировании, были идентифицированы с помощью нашего анализа, например, прецентральная извилина, и в принципе могут иметь отношение к предстоящему нажатию кнопки, чтобы сообщить о субъективном восприятии стимула.Мы специально нацелены на такую предвзятость двигательной подготовки в рамках контрольного эксперимента, в котором участник не мог априори предсказать, как сообщить о сознательном восприятии (то есть о нажатии или удержании нажатия кнопки), пока не появится ответная подсказка. Важно отметить, что мы не обнаружили какого-либо значимого декодирования, когда испытания, используемые для анализа, были отсортированы по типу ответа (например, с фактическим нажатием кнопки участником или без него) по сравнению с субъективным отчетом об обнаружении ( SI Приложение , рис.S3 B и C ). Такие результаты могут говорить в пользу общего моторного планирования (49) или деятельности, связанной с процессами принятия решений, в таких парадигмах принудительного выбора (50, 51).
Позднее вовлечение всей первичной сенсорной коры.
Некоторые результаты декодирования внутри модальностей выявили неспецифическое первичное вовлечение коры, в то время как декодирование выполнялось на другой сенсорной модальности. Например, во время слуховой стимуляции, близкой к пороговой, основная точность декодирования нейронной активности, предсказывающей сознательное восприятие, была обнаружена не только в слуховой, но и в зрительной коре головного мозга (рис.4, верхний ряд и левый столбец ). Интересно, что наш окончательный анализ показал и подтвердил, что первичные сенсорные области сильно участвуют в декодировании сознательного восприятия через сенсорные модальности. Более того, такие области мозга в основном были обнаружены в течение последнего исследованного периода времени после первого основного поражения лобно-теменных областей (рис. 5). Эти важные результаты предполагают, что сенсорная кора из определенной модальности содержит достаточно информации, чтобы позволить декодирование перцептивного сознательного доступа в другой другой сенсорной модальности.Эти результаты указывают на позднюю активную роль первичной коры над тремя различными сенсорными системами (Рис. 5). В одном исследовании сообщалось об эффективном декодировании категорий визуальных объектов в ранней соматосенсорной коре с использованием функциональной МРТ (FMRI) и многомерного анализа паттернов (52). Другой эксперимент с фМРТ показал, что сенсорная кора, по-видимому, модулируется через общую надрамодальную лобно-теменную сеть, что свидетельствует об общности механизма внимания в отношении ожидаемой слуховой, тактильной и визуальной информации (53).Однако в нашем исследовании мы демонстрируем, как локальная мозговая активность из разных сенсорных областей обнаруживает определенную динамику, позволяющую обобщать с течением времени для декодирования поведенческого результата субъективного восприятия в другой сенсорной модальности. Эти результаты говорят в пользу интимных кросс-модальных взаимодействий между модальностями восприятия (54). Наши результаты повторяют более ранние сообщения (для нескольких модальностей в одном исследовании) о том, что сознательный доступ к околопороговым стимулам не вызван различиями в ранней, в основном восходящей активацией, а скорее включает более поздние широко распространенные и повторно входящие нейронные паттерны (2, 3 , 6).
Наконец, наши результаты показывают, что первичные сенсорные области остаются важными в латентный период после начала стимула для разрешения восприятия стимула по разным сенсорным модальностям. Мы предполагаем, что эта сеть могла бы улучшить обработку поведенческих сигналов, в данном случае сенсорных целей. Хотя интеграция классически унимодальных первичных сенсорных областей коры в иерархию обработки сенсорной информации хорошо известна (55), некоторые исследования предполагают мультисенсорную роль первичных корковых областей (56, 57).
Сегодня остается неизвестным, как такие мультисенсорные реакции могут быть связаны с несенсорным сознательным восприятием человека у человека. Поскольку сенсорные модальности обычно переплетаются в реальной жизни, наши выводы о супрамодальной сети, которая может поддерживать как сознательный доступ, так и функции внимания, имеют более высокую экологическую ценность, чем результаты предыдущих исследований сознательного восприятия для одной сенсорной модальности.
На самом деле, наши результаты согласуются с продолжающимися дебатами в нейробиологии, которые спрашивают, в какой степени мультисенсорная интеграция проявляется уже в первичных сенсорных областях (57, 58).Исследования на животных предоставили убедительные доказательства того, что неокортекс по сути является мультисенсорным (59). Здесь наши данные говорят в пользу мультисенсорного взаимодействия в первичной и ассоциативной коре. Интересно, что предыдущее исследование фМРТ с использованием многомерного декодирования выявило различные механизмы, управляющие аудиовизуальной интеграцией первичной и ассоциативной коры, необходимые для пространственной ориентации и взаимодействия в мультисенсорном мире (60).
Заключение
Мы успешно охарактеризовали общие закономерности во времени и пространстве, предполагая обобщение связанной с сознанием активности мозга на различные сенсорные задачи NT.Наше исследование прокладывает путь для будущих исследований с использованием методов с более точным пространственным разрешением, таких как функциональная магнитно-резонансная томография, для детального изображения задействованной сети мозга. В этом исследовании сообщается о значительном пространственно-временном декодировании различных сенсорных модальностей в эксперименте по восприятию, близкому к пороговому. Действительно, наши результаты говорят в пользу существования стабильных и надрамодальных паттернов мозговой активности, распределенных во времени и вовлекающих, казалось бы, не связанные с задачами первичные сенсорные коры.Стабильность паттернов мозговой активности при различных сенсорных модальностях, представленная в этом исследовании, на сегодняшний день является наиболее прямым доказательством общей сетевой активации, ведущей к сознательному доступу (2). Более того, наши результаты дополняют недавние замечательные демонстрации применения методов декодирования и временного обобщения к MEG (21–23, 61) и показывают многообещающее применение методов MVPA для анализа прожектором на уровне источника с акцентом на временную динамику сознания. восприятие.
Материалы и методы
Участники.
Двадцать пять здоровых добровольцев приняли участие в первоначальном эксперименте, проведенном в Тренто, и 21 здоровый доброволец принял участие в контрольном эксперименте, проведенном в Зальцбурге. У всех участников было нормальное зрение или зрение с поправкой на нормальное, неврологических или психических расстройств не было. Три участника начального эксперимента и один участник контрольного эксперимента были исключены из анализа из-за чрезмерного количества артефактов в данных MEG, что привело к недостаточному количеству испытаний на одно условие после отклонения артефакта (менее 30 испытаний по крайней мере для одного условия).Кроме того, в каждом эксперименте шесть участников были исключены из анализа, потому что частота ложных срабатываний превышала 30% и / или уровень обнаружения, близкий к пороговому, был более 85% или ниже 15% по крайней мере для одной сенсорной модальности (из-за сбоя идентификации порога сложность использования отображения кнопок ответа во время контрольного эксперимента, также остается менее 30 испытаний по крайней мере для одного релевантного состояния в одной сенсорной модальности: обнаружено или необнаружено). Остальные 16 участников (11 женщин, средний возраст 28 лет.8 л; SD, 3,4 года) для начального эксперимента и 14 участников (9 женщин, средний возраст 26,4 года; SD, 6,4 года) для контрольного эксперимента сообщили о нормальном тактильном и слуховом восприятии. Комитет по этике Университета Тренто и Университета Зальцбурга, соответственно, одобрил протоколы экспериментов, которые использовались с письменного информированного согласия каждого участника.
Стимулы.
Чтобы участник не слышал никаких слуховых сигналов, вызванных пьезоэлектрическим стимулятором во время тактильной стимуляции, в течение всего эксперимента (включая тренировочные блоки) подавался бинауральный белый шум.Слуховые стимулы подавались бинаурально с использованием MEG-совместимых трубных внутриканальных наушников (SOUNDPixx; VPixx Technologies). Короткие всплески белого шума длительностью 50 мс генерировались с помощью Matlab и умножались с помощью окна Ханнинга для получения мягкого включения и смещения. Участники должны были обнаруживать короткие всплески белого шума, близкие к их порогу слуха (27). Интенсивность таких кратковременных целевых слуховых стимулов определялась до эксперимента, чтобы они возникали из фоновой стимуляции постоянным белым шумом.Визуальные стимулы представляли собой эллипсоид Габора (наклон 45 °; радиус 1,4 °; частота 0,1 Гц; фаза 90; сигма Гаусса 10), обратно проецируемый на полупрозрачный экран проектором Propixx DLP (VPixx Technologies) с частотой обновления 180 °. кадров в секунду. На черном фоне экрана в качестве точки фиксации использовался центральный серый круг фиксации (радиус 2,5 °) с центральной белой точкой. Стимулы предъявлялись в течение 50 мс в центре экрана на расстоянии 110 см. Тактильные стимулы подавались с помощью стимуляции в течение 50 мс на кончик левого указательного пальца с использованием модуля пьезоэлектрического стимулятора (Quaerosys) для одного пальца с стержнями 2 × 4, которые можно поднять максимум на 1 мм.Модуль был прикреплен к пальцу с помощью ленты, а левая рука участника была смягчена, чтобы предотвратить любое непреднамеренное давление на модуль (28). Для контрольного эксперимента (проведенного в другой лаборатории, например, в Зальцбурге) установки визуальной, слуховой и тактильной стимуляции были идентичны, но мы использовали другую систему вибротактильного стимулятора MEG / MRI (CM3; Cortical Metrics).
Задача и конструкция.
Участники выполнили три блока задачи восприятия NT. Каждый блок включал три отдельных прогона (по 100 испытаний каждый) для каждой сенсорной модальности: тактильной (Т), слуховой (А) и визуальной (V).Короткий перерыв (~ 1 мин) отделял каждую пробежку, а более длительные перерывы (~ 4 мин) предоставлялись участникам после каждого блока. Внутри блока прогоны чередовались в одном и том же порядке внутри темы и были псевдослучайно распределены по темам (например, тема 1 = TVA-TVA-TVA; тема 2 = НДС-НДС-НДС;…). Участников попросили зафиксировать центральную белую точку в сером центральном круге в центре экрана на протяжении всего эксперимента, чтобы минимизировать движения глаз.
Был проведен короткий обучающий цикл с 20 попытками, чтобы убедиться, что участники поняли задание.Затем, в ходе трех различных тренировок перед основным экспериментом, индивидуальные пороги восприятия участников (тактильные, слуховые и визуальные) определялись в экранированной комнате. Для первоначального эксперимента использовалась процедура лестницы один вверх / один вниз с двумя произвольно чередующимися лестницами (одна вверх и одна вниз) с фиксированными размерами шагов. Для контрольного эксперимента мы использовали байесовский протокол активной выборки для оценки психометрического наклона и порога для каждого участника (62).После определения с помощью этих лестничных процедур все интенсивности стимуляции, близкие к пороговой, оставались стабильными в течение каждого блока всего эксперимента для данного участника. Все значения интенсивности стимуляции можно найти в приложении SI , таблица S1.
Основной эксперимент состоял из задачи обнаружения (рис. 1 A ). В начале каждого пробега участникам говорили, что в каждом испытании слабый стимул (тактильный, слуховой или визуальный в зависимости от пробежки) может быть представлен через случайные промежутки времени.Через пятьсот миллисекунд после начала действия целевого стимула участникам предлагалось указать, почувствовали ли они стимул, с помощью вопросительного знака на экране (максимальное время ответа: 2 с). Ответы давались с использованием MEG-совместимых блоков ответов с указательным и средним пальцами правой руки (сопоставление кнопок ответа было уравновешено среди участников). Затем испытания были разделены на совпадения (обнаруженный стимул) и пропущенные (необнаруженный стимул) в соответствии с ответами участников. Испытания без ответа были отклонены.Испытания по улову (интенсивность стимуляции выше порога восприятия) и фиктивному (отсутствие стимуляции) были использованы для контроля ложных тревог и корректировки показателей отклонения в ходе эксперимента. Всего было проведено девять прогонов по 100 испытаний в каждом (всего 300 испытаний для каждой сенсорной модальности). Каждое испытание начиналось с переменного интервала (от 1,3 до 1,8 с, случайное распределение), за которым следовали экспериментальный стимул, близкий к пороговому (80 за запуск), фиктивный стимул (10 за запуск) или стимул ловли (10 за запуск) 50 мс каждый.Каждый запуск длился около 5 мин. Весь эксперимент длился ∼1 час.
В контрольном эксперименте использовались идентичные временные параметры. Однако для управления картированием моторной реакции использовался специальный дизайн экрана ответа. Для каждого испытания участники должны использовать разные карты ответов, связанные с цветом круга вокруг вопросительного знака на экране ответов. Использовались два цвета (синий или желтый), которые отображались случайным образом после каждого испытания во время контрольного эксперимента.Один цвет был связан с правилом сопоставления ответов «нажимайте кнопку, только если есть стимуляция» (для условия, близкого к пороговому, обнаружено), а другой цвет был связан с правилом сопоставления противоположных ответов «нажимайте кнопку, только если есть стимуляция». нет стимуляции »(для околопорогового состояния, не обнаружено). Связь между отображением одного ответа и определенным цветом (синим или желтым) была фиксированной для одного участника, но была предопределена случайным образом для разных участников. Важно отметить, что откладывая отображение ответа до момента после предъявления стимула (для индивидуума) непредсказуемым образом, нейронные паттерны в течение соответствующих периодов предположительно не могут быть искажены выбором / подготовкой ответа.Оба эксперимента были запрограммированы в Matlab с использованием пакета инструментов Psychophysics Toolbox с открытым исходным кодом (63).
Сбор и предварительная обработка данных MEG.
MEG было записано с частотой дискретизации 1 кГц с использованием 306-канальной (204 планарных градиентометра первого порядка, 102 магнитометра) системы VectorView MEG для первого эксперимента в Тренто и системы Triux MEG для контрольного эксперимента в Зальцбурге (Elekta -Neuromag Ltd.) в помещении с магнитным экраном (AK3B; Vakuumschmelze). Перед экспериментами для каждого участника были получены индивидуальные формы головы, включая реперные точки (назион и преаурикулярные точки) и около 300 оцифрованных точек на коже черепа с помощью дигитайзера Polhemus Fastrak.Положение головы людей относительно датчиков МЭГ непрерывно контролировалось в течение прогона с помощью пяти катушек. Движение головы внутри и между блоками не превышало 1 см.
Данные были проанализированы с использованием набора инструментов Fieldtrip (64) и набора инструментов CoSMoMVPA (65) в сочетании с MATLAB 8.5 (MathWorks). Сначала к непрерывным данным применялся фильтр верхних частот с частотой 0,1 Гц (КИХ-фильтр с полосой перехода 0,1 Гц). Затем данные были сегментированы от 1000 мс до начала до 1000 мс после начала целевой стимуляции и уменьшены до 512 Гц.Испытания, содержащие физиологические артефакты или артефакты приобретения, были отклонены. Процедура полуавтоматического обнаружения артефактов выявила статистические выбросы испытаний и каналов в наборах данных с использованием набора различных итоговых статистических данных (дисперсия, максимальная абсолютная амплитуда, максимальное значение z). Эти испытания и каналы были удалены из каждого набора данных. Наконец, данные были визуально проверены, и все оставшиеся испытания и каналы с артефактами были удалены вручную. Среди испытуемых было отклонено в среднем пять каналов (± 2 стандартное отклонение).Плохие каналы были исключены из всего набора данных. Подробный отчет об оставшемся количестве испытаний по каждому условию для каждого участника можно найти в SI Приложение , Таблица S1. Наконец, во всех дальнейших анализах и в каждой сенсорной модальности для каждого субъекта случайным образом было выбрано равное количество обнаруженных и необнаруженных испытаний, чтобы предотвратить любую систематическую ошибку в зависимости от условий (66).
Анализ источников.
Нейронная активность, вызванная началом стимула, была исследована путем вычисления ERF.Для всех анализов на уровне источника предварительно обработанные данные подвергались фильтрации нижних частот с частотой 30 Гц и проецировались на уровень источника с использованием анализа формирователя луча с линейно ограниченной минимальной дисперсией (LCMV) (67). Для каждого участника были рассчитаны модели головы с одной оболочкой реалистичной формы (68) путем сопоставления форм головы участников либо с их структурной МРТ, либо — когда не было индивидуальной МРТ (три участника и два участника, для начального эксперимента и контрольный эксперимент, соответственно) — со стандартным мозгом из Монреальского неврологического института (MNI), деформированным до индивидуальной формы головы.Сетка с разрешением 1,5 см на основе шаблона мозга MNI была преобразована в объем мозга каждого участника. Общий пространственный фильтр (для каждой точки сетки и каждого участника) был вычислен с использованием полей отведений и общей ковариационной матрицы с учетом данных из обоих условий (обнаруженных и необнаруженных или пойманных и фиктивных) для каждой сенсорной модальности отдельно. Ковариационное окно для расчета фильтра формирователя луча было основано на 200 мс до и 500 мс после стимула. Затем с помощью этого общего фильтра было оценено пространственное распределение мощности для каждого испытания отдельно.Полученные данные были усреднены относительно начала стимула во всех условиях (обнаруженный, необнаруженный, пойманный и фиктивный) для каждой сенсорной модальности. Только для целей визуализации к усредненным данным уровня источника применялась базовая коррекция путем вычитания временного окна от предварительного стимула 200 мс до начала стимула. Основываясь на значительном различии между связанными с событиями полями двух состояний во времени для каждой сенсорной модальности, локализация источника была выполнена с ограничением для конкретных интересующих временных окон.Все исходные изображения были интерполированы из исходного разрешения на раздутую поверхность головного мозга шаблона MNI, доступного в программном пакете Caret (69). Соответствующие координаты MNI и метки локализованных областей мозга были идентифицированы с помощью анатомического атласа головного мозга (атлас AAL; ссылка 70) и атласа сетевой парцелляции (29). Анализ источников данных МЭГ — это по своей сути недооцененная проблема, и единственного решения не существует. Кроме того, невозможно избежать утечки из источника, что еще больше снижает точность любого анализа.Наконец, мы напоминаем читателю, что мы не ожидаем точности более 3 см от наших результатов, потому что мы использовали стандартную локализацию источника LCMV с сеткой 1,5 см. Другими словами, исходные графики следует рассматривать как довольно убедительные доказательства только для основных областей мозга.
декодирование MVPA.
Декодирование MVPA выполнялось в течение периода от 0 до 500 мс после появления стимула на основе нормализованных (оцененных по z) данных источника однократного испытания с пониженной дискретизацией до 100 Гц (то есть с шагом по времени 10 мс).Мы использовали многомерный анализ паттернов, реализованный в CoSMoMVPA (65), чтобы определить, когда и какой тип общей сети между сенсорными модальностями активируется во время задачи обнаружения, близкого к пороговому. Мы определили два класса для декодирования, связанных с поведенческим результатом задачи (обнаруженный и необнаруженный). Для декодирования в рамках одной и той же сенсорной модальности исходные данные однократного испытания были случайным образом отнесены к одному из двух фрагментов (половина исходных данных).
Для декодирования всех сенсорных модальностей вместе исходные данные однократного испытания были псевдослучайно назначены одному из двух фрагментов с половиной исходных данных для каждой сенсорной модальности в каждом фрагменте.Данные были классифицированы с использованием процедуры двойной перекрестной проверки, когда байесовский классификатор предсказал условия испытаний в одном фрагменте после обучения на данных из другого фрагмента. Для декодирования между различными сенсорными модальностями исходные данные одного испытания одной модальности были назначены одному тестируемому блоку, а испытания из других модальностей были назначены обучающему блоку. Количество целевых категорий (например, обнаруженные / необнаруженные) было сбалансировано в каждом обучающем разделе и для каждой сенсорной модальности.Данные испытаний в равной степени разделены на блоки (т.е. у нас есть одинаковое количество трех прогонов и испытаний блока для каждой модальности в каждом отдельном блоке, используемом для классификации). Разделы обучения и тестирования всегда содержали разные наборы данных.
Во-первых, метод временного обобщения был использован для изучения способности каждого классификатора в разные моменты времени в обучающей выборке обобщать для каждой временной точки в наборе тестирования (21). В этом анализе мы использовали особенности локальных окрестностей во временном пространстве (временной радиус 10 мс: для каждого временного шага мы включали в качестве дополнительных функций предыдущую и следующую временные точки выборки).Мы сгенерировали матрицы временного обобщения точности декодирования задач (обнаружено / необнаружено), сопоставив время обучения классификатора со временем его тестирования. Обобщение точности декодирования с течением времени рассчитывалось для всех испытаний и систематически зависело от конкретного меж- или внутрисенсорного декодирования. Сообщаемая средняя точность классификатора для каждой временной точки соответствует среднему групповому значению индивидуального эффекта: способности классификаторов отличать обнаруженные испытания от необнаруженных испытаний.Мы суммировали временное обобщение, сохранив лишь значительную точность для декодирования каждой сенсорной модальности. Точности значимых классификаторов были нормализованы между 0 и 1, yt = xt − min (x) max (x) −min (x), [1]
, где x — переменная всех значимых точности декодирования, а xt — заданная значимая точность в момент времени t. Затем нормализованная точность (yt) была усреднена для значительного времени тестирования и условий декодирования. Количество значимых обобщений классификатора по временным точкам тестирования и соответствующие усредненные нормализованные точности были представлены по измерению времени обучения (рис.3 B и 5 B ). Для всех значимых моментов времени, определенных ранее, мы провели «прожекторный» анализ по источникам мозга и структуре временного соседства. В этом анализе мы использовали особенности локальных окрестностей в исходном и временном пространстве. Мы использовали временной радиус 10 мс и радиус источника 3 см. Все результаты значимой точности прожектора были усреднены по времени, и только максимальная достоверность 10% была указана на картах мозга для каждого условия декодирования сенсорной модальности (рис.4) или для всех условий вместе (рис. 5 C ).
Наконец, мы применили тот же тип анализа ко всем сенсорным модальностям, взяв все блоки вместе с обнаруженными и необнаруженными испытаниями NT (уравновешенными в каждой сенсорной модальности). Для контрольного эксперимента мы уравняли испытания на основе дизайна 2 × 2 с отчетом об обнаружении (обнаружено или необнаружено) и типом реакции («нажатие кнопки = ответ» или «нет ответа»), так что мы получили такое же количество испытаний. внутри каждой категории (т.е., класс) для каждой сенсорной модальности. Мы выполнили аналогичный анализ декодирования, используя другое определение класса: либо обнаруженный, либо необнаруженный, либо ответ против отсутствия ответа ( SI Приложение , рис. S3 B и C ).
Статистический анализ.
Показатели обнаружения в экспериментальных испытаниях были статистически сравнены с показателями вылова и фиктивных испытаний с использованием зависимых выборок t тестов. Что касается данных МЭГ, то основной статистический контраст был между испытаниями, в которых участники сообщали об обнаружении стимула, и испытаниями, в которых они этого не делали (обнаружено vs.необнаружены).
Вызванный ответ на уровне источника тестировался на уровне группы для каждой из сенсорных модальностей. Чтобы устранить полярность, статистические данные были рассчитаны на основе абсолютных значений откликов, связанных с событиями на уровне источника. На основе глобального среднего значения всех точек сетки мы сначала определили соответствующие периоды времени с максимальной разницей между условиями (обнаруженные и необнаруженные), выполнив групповой анализ с последовательными зависимыми тестами t между 0 и 500 мс после появления стимула с использованием скользящего окна. 30 мс с перекрытием 10 мс.Значения P были скорректированы для множественных сравнений с использованием поправки Бонферрони. Затем, чтобы получить пространственные генераторы, способствующие этому эффекту, обнаруженные и необнаруженные условия были сопоставлены для определенных периодов времени с помощью группового статистического анализа с использованием непараметрических тестов перестановки на основе кластеров с рандомизацией Монте-Карло по точкам сетки, контролирующим множественные сравнения (71).
Результаты многомерного анализа прожектором, различающего условия, были протестированы на уровне группы путем сравнения полученных индивидуальных карт точности с уровнем вероятности (50%) с использованием непараметрического подхода, реализованного в CoSMoMVPA (65), приняв 10000 перестановок для создания нулевого распределения.Значения P были установлены на уровне P <0,005 для коррекции на уровне кластера для контроля множественных сравнений с использованием беспорогового метода кластеризации (72), который был использован и подтвержден для данных MEG / EEG (40, 73) . Результаты временного обобщения на уровне группы были определены с использованием маски с скорректированным z-показателем> 2,58 (или P , скорректированным <0,005) (Фиг.3 A и 5 A ). Временные точки, превышающие этот порог, были идентифицированы и зарегистрированы для каждого временного интервала обучающих данных, чтобы визуализировать, насколько долгое обобщение было значимым для данных тестирования (рис.3 B и 5 B ). Карты мозга со значительной точностью, полученные в результате анализа прожектором в ранее определенные моменты времени, были представлены для каждого условия декодирования. Максимальные 10% усредненной точности были изображены для каждого значимого кластера декодирования на картах мозга (рис. 4 и 5).
Доступность данных.
Версия данных с пониженной дискретизацией (до 100 Гц) доступна в общедоступном репозитории OSF (https://osf.io/E5PMY/). Исходные необработанные данные без повторной выборки доступны по разумному запросу у соответствующего автора.Код анализа данных доступен в репозитории GitLab соответствующего автора (https://gitlab.com/gaetansanchez).
Благодарности
Эта работа была поддержана Европейским исследовательским советом (ERC) (Окно в сознание [WIN2CON], Стартовый грант ERC [StG] 283404). Мы благодарим Джулию Фрей за ее огромную поддержку во время сбора данных.
Сноски
Вклад авторов: G.S. и N.W. спланированное исследование; G.S., T.H., M.F. и G.D. проводили исследования; Т.Х. и Г.Д. предоставили новые реагенты / аналитические инструменты; G.S. проанализировал данные; и G.S. и N.W. написал газету.
Авторы заявляют об отсутствии конкурирующей заинтересованности.
Эта статья представляет собой прямое представление PNAS.
Размещение данных: версия исходных данных с пониженной дискретизацией (до 100 Гц) доступна в общедоступном репозитории OSF (https://osf.io/E5PMY/). Исходные данные без повторной выборки доступны по разумному запросу у соответствующего автора.Код анализа данных доступен в репозитории GitLab соответствующего автора (https://gitlab.com/gaetansanchez).
Эта статья содержит вспомогательную информацию в Интернете по адресу https://www.pnas.org/lookup/suppl/doi:10.1073/pnas.1
4117/-/DCSupplemental.
- Copyright © 2020 Автор (ы). Опубликовано PNAS.
Нейронные механизмы контроля внимания за объектами: декодирование альфа-канала ЭЭГ при прогнозировании лиц, сцен и инструментов
Аннотация
Механизмы выбора внимания в зрительной коре включают изменения колебательной активности в альфа-диапазоне ЭЭГ (8–12 Гц), со снижением альфа, указывающим на очаговое корковое усиление, и увеличенным альфа, указывающим на подавление.Это наблюдалось для пространственного избирательного внимания и внимания к характеристикам стимула, таким как цвет по сравнению с движением. Мы исследовали, включает ли внимание к объектам подобные альфа-опосредованные изменения фокальной корковой возбудимости. В эксперименте 1 20 добровольцев (8 мужчин; 12 женщин) были направлены (прогноз 80%) на пробную основу к различным объектам (лицам, сценам или инструментам). Поддержка векторного машинного декодирования альфа-паттернов мощности показала, что поздно (задержка> 500 мс) в предварительном периоде от метки к цели только альфа ЭЭГ различалась с категорией объекта, который должен посещаться.В эксперименте 2, чтобы исключить возможность того, что расшифровка физических характеристик сигналов привела к нашим результатам, 25 участников (9 мужчин; 16 женщин) выполнили аналогичную задачу, в которой реплики не предсказывали категорию объекта. Альфа-декодирование теперь было значимым только в раннем (<200 мс) предварительном периоде. В эксперименте 3, чтобы исключить возможность того, что различия в постановке задач между разными категориями объектов привели к результатам нашего эксперимента 1, 12 участников (5 мужчин; 7 женщин) выполнили задачу прогнозирования, в которой задача распознавания различных объектов была идентична для разных категорий объектов. .Результаты повторили эксперимент 1. В совокупности эти результаты подтверждают гипотезу о том, что нейронные механизмы зрительного избирательного внимания включают фокальные корковые изменения в альфа-мощности не только для простого пространственного и особенного внимания, но и для высокоуровневого объектного внимания у людей.
ЗНАЧИМОЕ ЗАЯВЛЕНИЕ Внимание — это когнитивная функция, которая позволяет выбирать релевантную информацию из сенсорных входов, чтобы ее можно было обработать для поддержки целенаправленного поведения.Визуальное внимание широко изучается, но нейронные механизмы, лежащие в основе отбора визуальной информации, остаются неясными. Колебательная активность ЭЭГ в альфа-диапазоне (8–12 Гц) нервных популяций, восприимчивых к целевым визуальным стимулам, может быть частью механизма, поскольку считается, что альфа отражает фокальную нервную возбудимость. Здесь мы показываем, что активность альфа-диапазона, измеренная с помощью ЭЭГ скальпа участников, варьируется в зависимости от конкретной категории объекта, выбранного вниманием. Это открытие подтверждает гипотезу о том, что активность альфа-диапазона является фундаментальным компонентом нейронных механизмов внимания.
Введение
Селективное внимание — это фундаментальная когнитивная способность, которая облегчает обработку релевантной для задачи перцепционной информации и подавляет отвлекающие сигналы. Влияние внимания на восприятие было продемонстрировано в улучшении поведенческих характеристик (Познер, 1980) и изменении кривых психофизической настройки (Карраско и Барбот, 2019). У людей эти преимущества восприятия присутствующих стимулов сочетаются с повышенными сенсорно-вызванными потенциалами (Van Voorhis and Hillyard, 1977; Eason, 1981; Mangun and Hillyard, 1991; Eimer, 1996; Luck et al., 2000) и усиление гемодинамических реакций (Corbetta et al., 1990; Heinze et al., 1994; Mangun et al., 1998; Tootell et al., 1998; Martínez et al., 1999; Hopfinger et al., 2000; Giesbrecht et al., 2003). У животных электрофизиологические записи показывают, что сенсорные нейроны, реагирующие на обслуживаемые раздражители, имеют более высокую частоту возбуждения, чем таковые на необслуживаемые раздражители (Moran and Desimone, 1985; Luck et al., 1997), улучшенное соотношение сигнал-шум при передаче информации (Mitchell et al. ., 2009; Briggs et al., 2013) и усиленные колебательные ответы (Fries et al., 2001), которые поддерживают более высокую межреальную функциональную взаимосвязь (Bosman et al., 2012).
Большинство моделей избирательного внимания постулируют, что нисходящие управляющие сигналы внимания, возникающие в корковых сетях более высокого уровня, искажают обработку сенсорных систем (Nobre et al., 1997; Kastner et al., 1999; Corbetta et al., 2000; Hopfinger). и др., 2000; Корбетта, Шульман, 2002; Петерсен, Познер, 2012). Однако остается неясным, как именно нисходящие сигналы влияют на сенсорную обработку в сенсорной коре.Один из возможных механизмов включает модуляцию альфа-колебаний ЭЭГ (8–12 Гц). Когда скрытое внимание направлено на одну сторону поля зрения, альфа-сигнал сильнее подавляется в противоположном полушарии (Worden et al., 2000; Sauseng et al., 2005; Thut et al., 2006; Rajagovindan and Ding, 2011). Считается, что это латерализованное уменьшение альфа-канала отражает повышение возбудимости коры в сенсорных нейронах, соответствующих задаче, для облегчения обработки предстоящих стимулов (Romei et al., 2008; Дженсен и Мазахери, 2010; Климеш, 2012). Связь между нисходящей активностью в лобно-теменной системе контроля внимания и альфа в сенсорной коре была предположена в исследованиях с использованием транскраниальной магнитной стимуляции для контроля областей (Capotosto et al., 2009, 2017), одновременных исследованиях ЭЭГ-фМРТ (Zumer et al., 2014; Liu et al., 2016) и магнитоэнцефалографии (Popov et al., 2017).
Хотя большинство исследований роли альфы в избирательном зрительном внимании сосредоточено на пространственном внимании, альфа-механизмы могут быть более общими (Jensen and Mazaheri, 2010).Селективное внимание к низкоуровневым визуальным характеристикам — движению по сравнению с цветом — также, как было показано, модулирует альфа-канал, который был локализован в областях MT и V4 с использованием моделирования ЭЭГ у людей (Snyder and Foxe, 2010). Следовательно, похоже, что связанная с вниманием альфа-модуляция может происходить на нескольких ранних уровнях сенсорной обработки в зрительной системе, причем локус альфа-модуляции функционально соответствует типу визуальной информации, на которую нацелено внимание. Неизвестно, участвует ли альфа-механизм также в контроле внимания над более высокими уровнями корковой визуальной обработки, например, вниманием к объектам.В настоящем исследовании мы проверили гипотезу о том, что альфа-модуляция является механизмом избирательного внимания к объектам путем записи ЭЭГ участников, выполняющих задачу упреждающего внимания к объекту, с использованием следующих трех категорий объектов: лица, сцены и инструменты. Используя методы декодирования ЭЭГ, мы подтверждаем эту гипотезу, обнаруживая объектно-специфические модуляции альфа-канала во время упреждающего внимания к различным категориям объектов.
Материалы и методы
Обзор
Настоящее исследование состояло из трех экспериментов.Эксперимент 1 является основным экспериментом, в котором мы проверяли, можно ли различить топологию альфа-диапазона ЭЭГ в зависимости от объектно-ориентированного состояния внимания. Анализ данных ЭЭГ включал построение топографической карты разности мощностей и декодирование мощности альфа-диапазона опорным вектором (SVM) для количественной оценки того, содержит ли альфа-диапазон ЭЭГ информацию о наблюдаемой категории объекта. В экспериментах 2 и 3 мы проверили две альтернативные интерпретации наших результатов из эксперимента 1.В частности, в эксперименте 2 мы проверили, могла ли точность декодирования в подготовительном периоде между началом сигнала и целевым началом, обнаруженная в эксперименте 1, быть основана на различиях в сенсорных процессах, вызываемых в зрительной системе различными стимулами сигнала, поскольку Свойства физических стимулов сигналов для трех различных условий внимания к объекту отличались друг от друга (треугольник против квадрата против круга). В эксперименте 3 мы исследовали, могли ли различия в альфа-топографии в разных условиях внимания к объекту в эксперименте 1 быть результатом разных наборов задач в трех условиях внимания объекта, а не отражением механизмов внимания на основе объектов в зрительной коре головного мозга.
Участники
Все участники были здоровыми студентами-волонтерами из Калифорнийского университета в Дэвисе; имел нормальное или скорректированное до нормального зрение; дали информированное согласие; и получили зачетное время или денежную компенсацию за свое время. В эксперименте 1 данные ЭЭГ были записаны у 22 добровольцев (8 мужчин; 14 женщин). Два добровольца решили прекратить свое участие в середине эксперимента; данные оставшихся 20 участников (8 мужчин; 12 женщин) использовались для всех анализов.В эксперименте 2 данные ЭЭГ были записаны у 29 студентов; наборы данных от 4 участников были отклонены на основании непримиримого шума в данных или несоответствия субъектов, в результате чего был получен окончательный набор данных от 25 участников (9 мужчин; 16 женщин), который был использован для дальнейшего анализа декодирования. В эксперименте 3 данные ЭЭГ были записаны у 12 добровольцев (5 мужчин; 7 женщин). Наборы данных от двух участников были отклонены на основании непримиримого шума в данных ЭЭГ, в результате чего был получен окончательный набор данных ЭЭГ от 10 участников (5 мужчин и 5 женщин), который был использован для дальнейшего анализа декодирования.
План эксперимента
В исследовании использовался дизайн внутри субъектов. В экспериментах 1 и 3 мы исследовали распределение альфа-мощности ЭЭГ на коже черепа в зависимости от категории обслуживаемых объектов в упреждающей задаче на внимание с тремя категориями объектов (лица, сцены и инструменты). В эксперименте 2 мы исследовали распределение мощности альфа-излучения ЭЭГ на коже черепа во время послеоперационного периода, когда три категории объектов не были посещены заранее. Подробная информация о задаче на внимание на объектном вызове, задаче без ответа и статистическом анализе представлена ниже.
Статистический анализ
Данные поведенческой реакции были проанализированы с помощью обобщенной линейной смешанной модели с гамма-распределением (Lo and Andrews, 2015) со случайным эффектом субъекта и фиксированными эффектами категории объекта и достоверности сигнала для количественной оценки эффекта достоверности сигнала. по времени реакции (RT).
Различия в топографии альфа-мощности скальпа на ЭЭГ в зависимости от состояния реплики были статистически проанализированы с использованием подхода декодирования SVM и непараметрического кластерного теста перестановок и моделирования Монте-Карло.Статистический тест на основе кластера использовался для устранения проблем с множественным сравнением, которые возникают, когда тесты — выполняются во все моменты времени в течение эпохи (Bae and Luck, 2018). Подробности статистического теста на альфа-мощность ЭЭГ описаны ниже.
Эксперимент 1
Аппараты и раздражители.
Участники удобно расположились в электрически экранированном звукопоглощающем помещении (ETS-Lindgren). Стимулы предъявлялись на светодиодном мониторе VIEWPixx / EEG (модель VPX-VPX-2006A, VPixx Technologies) на расстоянии просмотра 85 см, центрированном по вертикали на уровне глаз.Диагональ дисплея составляла 23,6 дюйма, разрешение — 1920 × 1080 пикселей, частота обновления — 120 Гц. Комната для записи и предметы в ней были окрашены в черный цвет, чтобы избежать отраженного света, и она слабо освещалась лампами постоянного тока.
Каждое испытание начиналось с псевдослучайно выбранного представления одного из трех возможных типов сигналов в течение 200 мс (треугольник 1 ° × 1 °, квадрат или круг, используя PsychToolbox; Brainard, 1997; Рис. 1 A ). Действительные сигналы информировали участников, какая категория целевых объектов (лицо, сцена или инструмент, соответственно), вероятно, появится впоследствии (вероятность 80%).Реплики располагались на 1 ° выше центральной точки фиксации. После псевдослучайно выбранных асинхронностей начала стимула (SOA; 1000–2500 мс) от начала сигнала, целевые стимулы (квадратное изображение 5 ° × 5 °) предъявлялись при фиксации в течение 100 мс. В случайных 20% испытаний реплики были недействительными, неправильно информируя участников о предстоящей категории целевых объектов. Для этих недействительных испытаний целевое изображение было отобрано с равной вероятностью из любой из двух категорий объектов без привязки. Все стимулы предъявлялись на сером фоне.Белая точка фиксации постоянно присутствовала в центре дисплея.
Рисунок 1.A , Пример пробной последовательности для задачи «Внимание». Каждое испытание начиналось с предъявления символической подсказки, которую испытуемые учили, предсказывали (80%) конкретную категорию объекта. После периода ожидания (от метки к цели), изменяющегося от 1,0 до 2,5 с, было представлено изображение объекта (лица, сцены или инструмента). В 20% испытаний было представлено одно из двух изображений цели без привязки.Испытуемые должны были быстро и точно различать аспекты изображений как в ожидаемых, так и в неожиданных условиях (подробности см. В тексте). B , Примеры изображений цели, представленные в задании на внимание. Изображения лиц, сцен и инструментов были выбраны из онлайн-баз данных.
Целевые изображения (Рис. 1 B ) были выбраны из 60 возможных изображений для каждой категории объектов. Все целевые изображения были собраны из Интернета. Изображения лиц были фронтальными, с нейтральным выражением, лицами белой национальности, обрезанными и помещенными на белом фоне (Righi et al., 2012). Полнокадровые изображения сцен были взяты из коллекции естественных сцен Техасского университета в Остине (Geisler and Perry, 2011) и коллекции сцен кампуса (Burge and Geisler, 2011). Обрезанные изображения инструментов на белом фоне были взяты из Банка стандартизированных стимулов (Brodeur et al., 2014). Псевдослучайно распределенный интервал между испытаниями (ITI; 1500–2500 мс) отделял целевое смещение от начала сигнала следующего испытания. Каждый набор из 60 изображений объектов состоял из 30 изображений следующих различных подкатегорий: мужские / женские лица, городские / природные сцены и инструменты с питанием / без питания.
Запись ЭЭГ.
Необработанные данные ЭЭГ были получены с помощью 64-канальной системы активных электродов Brain Products actiCAP (Brain Products) и оцифрованы с помощью входной платы и усилителя Neuroscan SynAmps2 (Compumedics). Сигналы были записаны с помощью программного обеспечения для сбора данных Scan 4.5 (Compumedics) с частотой дискретизации 1000 Гц и полосой пропускания от постоянного тока до 200 Гц. Шестьдесят четыре активных электрода Ag / AgCl помещали в подогнанные эластичные колпачки, используя следующий монтаж в соответствии с международной системой 10–10 (Jurcak et al., 2007): FP1, FP2, AF7, AF3, AFz, AF4, AF8, F7, F5, F3, F1, Fz, F2, F4, F6, F8, FT9, FT7, FC5, FC3, FC1, FCz, FC2, FC4, FC6, FT8, FT10, T7, C5, C3, C1, Cz, C2, C4, C6, T8, TP9, TP7, CP5, CP3, CP1, CPz, CP2, CP4, CP6, TP8, TP10, P7, P5, P3, P1, Pz, P2, P4, P6, P8, PO7, PO3, POz, PO4, PO8, PO9, O1, Oz, O 2 и PO10; с каналами AFz и FCz, назначенными как наземный и оперативный, соответственно. Кроме того, электроды на участках TP9 и TP10 были размещены непосредственно на левом и правом сосцевидном отростке.Электрод Cz был ориентирован на макушку головы каждого участника путем измерения спереди назад от назиона до начала и справа налево между преаурикулярными точками. Гель-электролит с высокой вязкостью наносили на каждое место электрода для облегчения проводимости между электродом и кожей головы, а значения импеданса поддерживались на уровне <25 кОм. Непрерывные данные сохранялись в отдельных файлах, соответствующих каждому пробному блоку парадигмы стимула.
Предварительная обработка ЭЭГ.
Все процедуры предварительной обработки данных были выполнены с помощью набора инструментов EEGLAB MATLAB (Delorme and Makeig, 2004).Для каждого участника все файлы данных ЭЭГ были объединены в единый набор данных перед обработкой данных. Каждый набор данных был визуально проверен на наличие плохих каналов, но таких каналов не наблюдалось. Данные были отфильтрованы с помощью окна Хэмминга sinc FIR (конечный импульсный отклик) (1–83 Гц), а затем субдискретизированы до 250 Гц. Данные были алгебраически привязаны к среднему значению для всех электродов, а затем были отфильтрованы нижние частоты до 40 Гц. Данные были привязаны к периоду от 500 мс до начала сигнала до 1000 мс после начала сигнала, так что ожидаемые данные всех испытаний можно было изучить вместе.Данные были визуально проверены, чтобы отметить и отклонить испытания с помощью морганий и движений глаз, которые произошли во время подачи сигнала. Затем была использована разложение независимого компонентного анализа для удаления артефактов, связанных с морганиями и движениями глаз.
Анализ ЭЭГ.
Мы использовали процедуру спектральной плотности мощности с функцией периодограммы (x) Matlab (длина окна, 500 мс; длина шага, 40 мс), чтобы извлечь мощность в альфа-диапазоне для каждого электрода, а также для каждого участника и сигнала. условие.Мощность в альфа-диапазоне рассчитывалась как среднее значение мощности от 8 до 12 Гц. Для каждого участника и условия сигнала результаты спектральной плотности мощности вычислялись в отдельных испытаниях, а затем усреднялись по испытаниям. Усредненные результаты спектральной плотности мощности использовались для визуального изучения топографии мощности альфа-диапазона в различных условиях сигнала.
Мы реализовали анализ декодирования, чтобы количественно оценить, было ли внимание объекта систематически связано с изменениями фазонезависимой топографии мощности альфа-диапазона в зависимости от условий.Эта процедура анализа была адаптирована из процедуры декодирования представлений рабочей памяти из ЭЭГ кожи головы (Bae and Luck, 2018).
Декодирование выполнялось независимо в каждый момент времени в эпохах. Мы реализовали нашу модель декодирования с помощью функции Matlab fitecoc (x) , чтобы использовать комбинацию SVM и алгоритмов выходного кодирования с исправлением ошибок (ECOC). Отдельный бинарный классификатор был обучен для каждого условия сигнала с использованием подхода «один против одного», при этом производительность классификатора была объединена в соответствии с подходом ECOC.Таким образом, декодирование считалось правильным, когда классификатор правильно определил условие реплики из трех возможных условий реплики, а вероятность выполнения была установлена на уровне 33,33% (одна треть).
Декодирование для каждой временной точки следовало шестикратной процедуре перекрестной проверки. Данные пяти шестых испытаний, выбранных случайным образом, были использованы для обучения классификатора правильной маркировке. Оставшаяся шестая часть испытаний использовалась для тестирования классификатора с помощью функции Matlab pred (x) .Вся эта процедура обучения и тестирования повторялась 10 раз, при этом новые данные для обучения и тестирования назначались случайным образом на каждой итерации. Для каждого условия сигнала, каждого участника и каждой временной точки точность декодирования рассчитывалась путем суммирования количества правильных маркировок в испытаниях и итерациях и деления на общее количество маркировок.
Мы усреднили вместе результаты декодирования для всех 10 итераций, чтобы проверить точность декодирования для всех участников в каждый момент времени в эпоху.В любой данный момент времени точность декодирования с высокой вероятностью предполагает, что альфа-топография содержит информацию о категории обслуживаемых объектов. Однако сравнения точности декодирования со случайностью самого по себе недостаточно для оценки надежности вывода, сделанного на основе точности декодирования. Несмотря на то, что односторонний тест t декодирования точности для разных субъектов против случайности даст значение t и результат статистической значимости для рассматриваемой временной точки, проведение одного и того же теста в каждой из 375 временных точек, включенных в нашу эпоху. потребует поправки на множественные поправки, что приведет к чрезмерно консервативным статистическим тестам.Поэтому, после исследования Bae and Luck (2018), мы использовали оценку значимости на основе моделирования методом Монте-Карло, чтобы выявить статистически значимые кластеры точности декодирования.
Статистическим методом Монте-Карло точность декодирования оценивалась по случайно выбранному целому числу (1, 2 или 3), представляющему экспериментальные условия, для каждой временной точки. Тест t точности классификации участников на случайность выполнялся в каждый момент времени для перемешанных данных.Были идентифицированы кластеры последовательных моментов времени с точностью декодирования, определенные как статистически значимые с помощью теста t , и масса кластера t была рассчитана для каждого кластера путем суммирования значений t , заданных каждым составляющим тестом t . Каждый кластер сэкономил т массы . Эта процедура была повторена 1000 раз, чтобы сгенерировать распределение масс t , чтобы представить нулевую гипотезу о том, что данный кластер масс t из нашего анализа декодирования, вероятно, был найден случайно.Значение массы t отсечки 95% было определено из нулевого распределения на основе перестановок и использовано в качестве отсечки, с которой можно было сравнивать массы кластера t , вычисленные на основе наших исходных данных декодирования. Кластеры последовательных моментов времени в исходных результатах декодирования с массами –, превышающими порог, основанный на перестановках, считались статистически значимыми.
Мы выполнили ту же процедуру декодирования фазонезависимой колебательной активности ЭЭГ в тета-диапазоне (4–7 Гц), бета-диапазоне (16–31 Гц) и гамма-диапазоне (32–40 Гц), чтобы проверить гипотезу, что объект Модуляции активности ЭЭГ, основанные на внимании, специфичны для альфа-диапазона.Для фильтрации данных ЭЭГ в бета- и гамма-диапазоне мы установили минимальный порядок фильтрации, равный трехкратному количеству отсчетов в экспериментальную эпоху. Для фильтрации по тета-диапазону мы установили минимальный порядок фильтрации, равный удвоенному количеству отсчетов, потому что длительность эпохи не была достаточно большой, чтобы позволить порядок фильтрации в три раза больше количества отсчетов.
Порядок действий.
Участники были проинструктированы сохранять фиксацию в центре экрана во время каждого испытания и предвосхищать категорию объекта, на которую указывает указатель, до тех пор, пока не появится целевое изображение.Кроме того, им было поручено указать подкатегорию объекта целевого изображения (например, мужчина / женщина) нажатием кнопки как можно быстрее и точнее в целевой презентации, используя кнопку указательного пальца для мужчин (лицо), природы (сцена) и питания. (инструмент) и нажмите кнопку среднего пальца для женщин (лицо), городских (сцена) и без питания (инструмент). Ответы регистрировались только во время ITI между целевым началом и следующим испытанием. Испытания были классифицированы как правильные, когда записанный ответ соответствовал подкатегории целевого изображения, и неправильный, когда ответ не совпадал или когда не было записанного ответа.Каждый блок экспериментов включал 42 испытания продолжительностью ~ 3 мин. Каждый участник выполнил 10 блоков эксперимента.
Эксперимент 2
Протоколы записи и анализа были идентичны протоколам эксперимента 1. Учитывая, что цель этого эксперимента состояла в том, чтобы проверить, могла ли точность декодирования в подготовительном периоде между началом сигнала и целевым началом, быть основана на различиях Что касается сенсорных процессов, вызываемых в зрительной системе различными репликами, мы модифицировали эксперимент 1, сделав реплики непредсказуемыми для предстоящей целевой категории.В соответствии с этой модификацией мы проинструктировали участников, что форма реплики неинформативна, и что представление реплики было просто для предупреждения их о том, что целевой стимул скоро появится. Участников не проинструктировали игнорировать форму реплики. Хотя временной ход различий в сенсорных ответах в ЭЭГ кожи головы, отфильтрованных до частот альфа-диапазона, трудно измерить, на основе предыдущей литературы (Bae and Luck, 2018) мы предсказали, что даже для альфы любой дифференцируемый вызванный стимулом сенсорная активность будет ограничена временным окном в пределах 200 мс после начала сигнала.Каждый участник выполнил 10 блоков эксперимента, в каждом блоке по 42 попытки.
Эксперимент 3
Протоколы записи и анализа были идентичны протоколам эксперимента 1. Целью этого эксперимента было выяснить, могли ли различия в альфа-топографии в разных условиях внимания объекта в эксперименте 1 быть результатом различных наборов задач в разных группах. три состояния объектного внимания, а не отражающие объектно-ориентированные механизмы внимания в зрительной коре.В частности, в условиях присутствия лица в эксперименте 1 участников проинструктировали различать, было ли представленное лицо мужским или женским, и указать свой выбор, используя поле кнопок с двумя кнопками под указательным и средним пальцами. В условии присутствия на сцене задача заключалась в том, чтобы отличить городские сцены от естественных с помощью тех же двух кнопок, а в условии присутствия инструмента задача заключалась в том, чтобы отличить питание от инструментов без питания с помощью тех же двух кнопок. Поскольку различаемые категории были разными в разных условиях (мужской / женский, городской / естественный, электроинструмент / ручной инструмент), возможно, что участники готовили разные наборы задач в разных условиях реплики в течение подготовительного периода.Например, после представления треугольной реплики участнику потребуется когнитивно сопоставить реакцию своего указательного пальца на идентификацию мужского лица и реакцию своего среднего пальца на идентификацию женского лица, тогда как это сопоставление будет другим, если Участнику был вручен квадратный кий. Эти различные наборы задач и сопоставления от зрительной коры головного мозга к подготовке двигательной реакции могли, возможно, управлять различными альфа-топографиями кожи головы в течение подготовительного периода.
Это объяснение не является взаимоисключающим с нашей интерпретацией, согласно которой альфа-топография скальпа отражает различное предварительное смещение внимания в визуальных областях, отобранных по категориям объектов, но, учитывая план эксперимента 1, нет способа узнать, одно, другое или оба отражены в различных альфа-паттернах. Поэтому мы провели эксперимент, который приравнял задачу ко всем условиям внимания к объекту, чтобы устранить любые различия в наборе задач, которые присутствовали в исходном эксперименте.Основываясь на нашей модели, согласно которой альфа — это механизм избирательного внимания к объектам в зрительной коре, в этом новом дизайне мы все еще должны наблюдать различные паттерны альфа-сигналов для подготовительного внимания к категориям объектов, которые должны быть выявлены при успешном декодировании на поздних этапах пути к целевому периоду.
Аппараты и раздражители.
Общая структура парадигмы для эксперимента 3 следовала парадигме эксперимента 1. В каждом испытании появлялась форма реплики, указывающая категорию объекта, который необходимо посетить.Формы реплик были идентичны таковым в эксперименте 1. Как и раньше, за репликой следовал подготовительный период, а затем появлялось изображение стимула. ITI разделяет изображение стимула и начало следующего испытания. Поведенческие ответы были собраны во время этого ITI. Диапазоны SOA и ITI оставались такими же, как в эксперименте 1.
Поведенческая задача для этого эксперимента заключалась в том, чтобы определить при каждом испытании, соответствует ли кратко представленное целевое изображение, принадлежащее к категории объектов, по которым осуществляется указание (лица, сцены или инструменты). в фокусе или размыто.В отличие от экспериментов 1 и 2, стимулы, подлежащие различению, представляли собой композицию изображения, принадлежащего целевой категории, наложенного на изображение, принадлежащее к категории отвлекающих факторов. Важно отметить, что и целевое изображение, и изображение-отвлекающий элемент в смеси могут быть в фокусе или размытыми независимо друг от друга; следовательно, задача не могла быть выполнена исключительно на основе внимания и реакции на присутствие или отсутствие размытия (см., например, результаты эксперимента 3).
Двадцать процентов испытаний были неправильно запрошены, что позволяет нам оценить влияние достоверности реплики на поведенческие характеристики.Для недействительных испытаний изображение стимула было составным из изображения из случайно выбранной категории объектов без привязки, наложенного на черно-белую шахматную доску. Шахматная доска также может быть размытой или в фокусе независимо от изображения объекта. Участников проинструктировали, что всякий раз, когда они сталкивались с испытанием, в котором смешанный стимул не включал изображение, принадлежащее к категории объекта с указанием, а вместо этого содержал только одно изображение объекта и наложение шахматной доски, они должны были указать, является ли изображение объекта без привязки в стимуле был расплывчатым или в фокусе.Мы предсказали, что участники будут медленнее реагировать на испытания с неверными указаниями, аналогично поведенческому эффекту валидности, наблюдаемому в парадигмах пространственного внимания с указанием указаний.
Изображения стимула охватывали квадрат 5 ° × 5 ° угла обзора. Для создания размытых изображений к изображениям применялось размытие по Гауссу со значением SD 2.
Все три категории объектов включали 40 различных индивидуальных изображений. В каждом испытании были нарисованы случайные изображения для создания составного изображения стимула. Изображения сцен и инструментов были взяты из тех же наборов изображений, что и для исходного эксперимента.Однако изображения лиц были взяты из другого набора изображений (Ma et al., 2015), потому что изображения лиц, использованные в первоначальном эксперименте, не имели достаточно высокого разрешения, чтобы обеспечить надежно заметные различия в размытых и не размытых условиях. Все изображения лиц были обрезаны до овалов с центром на лице и помещены на белом фоне.
В отличие от изображений сцены, которые содержали визуальные детали, охватывающие весь квадрат 5 ° × 5 °, изображения лиц и инструментов были установлены на белом фоне и поэтому не содержали визуальной информации до всех границ изображения.Следовательно, чтобы исключить возможность того, что участники могут использовать информацию о сигнале для фокусировки пространственного внимания вместо объектно-ориентированного внимания для выполнения размытого / сфокусированного различения в любом испытании, где изображение лица или инструмента было включено в составной стимул, положение этого изображение лица или инструмента было случайным образом смещено из центра.
Порядок действий.
Участники были проинструктированы как можно быстрее реагировать на целевой стимул, поэтому крайне важно, чтобы участники в течение подготовительного периода привлекали подготовительное внимание к категории объектов с указанием.Все участники были обучены как минимум 126 попыткам выполнения задания и смогли достичь не менее 60% точности ответа перед выполнением его в рамках сбора данных ЭЭГ; для этого продолжительность стимула была скорректирована для каждого участника на начальном этапе обучения. Эксперимент 3 был проведен в той же лабораторной среде, что и исходный эксперимент, и переменные среды были приравнены к параметрам исходного эксперимента.
Каждый участник выполнил 15 блоков эксперимента, каждый из которых включал 42 испытания, что в среднем представляло на 210 испытаний на одного субъекта больше, чем эксперимент 1.
Результаты
Эксперимент 1
Поведенческие результаты
Наблюдаемая точность отклика была высокой и одинаковой для всех условий объекта и условий достоверности (недопустимое лицо 96,6%; недопустимая сцена 97,1%; допустимое лицо 96,8%; допустимая сцена 96,7 %; действительный инструмент, 93,1%), за исключением недопустимого условия обслуживания (87,5%), которое мы рассмотрим ниже.
Чтобы определить, вызвала ли наша задача поведенческий эффект внимания, мы сравнили RT для определения целевых различий между испытаниями с действительной и недействительной подсказкой.Мы наблюдали более быстрые средние RT для действительных испытаний, чем для недействительных испытаний, усредняясь по условиям (рис. 2 A ) и для каждого условия отдельно (рис. 2 B ).
Рисунок 2.Поведенческие меры внимания в эксперименте 1. A , Ящичковые диаграммы данных о времени реакции для недействительных и достоверных испытаний для 20 субъектов, усредненные по состояниям внимания (объекта). Толстые горизонтальные линии внутри прямоугольников представляют собой медианные значения. Первый и третий квартили показаны как нижний и верхний края прямоугольника.Вертикальные линии проходят до самых крайних точек данных, за исключением выбросов. Точки над графиками представляют выбросы, которые были определены как любое значение, превышающее третий квартиль плюс 1,5 межквартильного размаха. Субъекты в целом были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимыми). B , Время реакции для действительных и недействительных испытаний отдельно для каждого состояния внимания. Субъекты были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимые) для каждой категории объектов.
Чтобы количественно оценить влияние достоверности реплики на RT, мы подобрали обобщенную линейную смешанную модель с гамма-распределением к данным RT (Lo and Andrews, 2015). Мы обнаружили значительный эффект валидности (действительный или недействительный, p <0,001). Модель также выявила значительный главный эффект категории объекта ( p <0,001) из-за более медленного общего времени реакции в категории инструмента. Таким образом, испытуемые были менее точны и медленнее реагировали на категорию инструментов.Несмотря на эти незначительные снижения производительности для категории инструментов, тем не менее наблюдался значительный поведенческий эффект внимания для категории инструментов, что свидетельствовало о том, что испытуемые использовали все три типа сигналов, чтобы подготовиться к распознаванию и реагированию на приближающиеся объекты.
Результаты альфа-топографии
Чтобы качественно оценить, была ли картина мощности альфа-излучения на электродах разной для упреждающего внимания к трем категориям объектов, на которые указывает последовательность, мы исследовали топографические графики мощности альфа-излучения для каждого состояния объекта в разные периоды времени после сигналов, но до появления целевых раздражителей.Чтобы выделить различия между альфа-топографиями между состояниями и контролировать неспецифические эффекты поведенческого возбуждения, мы создали попарные карты различий альфа-топографии одного состояния внимания объекта, вычтенного из другого состояния внимания объекта.
Мы наблюдали, что различия в альфа-топографии между условиями объекта возникали и развивались в течение периода упреждения (от сигнала к цели) (рис. 3). В топографиях посещаемость минус посещаемость (рис.3 A ), мы наблюдали повышенную альфа-мощность над левой задней частью скальпа и уменьшенную альфа-мощность над правой задней частью скальпа в течение периода упреждения, при этом латерализация становилась наиболее заметной при более длительных послеоперационных латентных периодах. В топографиях «лицо минус инструмент» (рис. 3 B ) картина была аналогичной в самые длинные латентные периоды, но была более изменчивой в промежуточные периоды времени. В топографиях посещаемости минус посещаемость (рис. 3 C ), паттерн альфа-различий отличался от тех, которые связаны с условиями посещаемости; при самых длительных послеоперационных латентных периодах картина силы альфа-излучения на коже черепа была обратной, чем на других картах разницы, причем сила альфа-излучения была выше слева, чем на правой задней части скальпа.В целом, наличие этих различий между состояниями согласуется с вариациями основных паттернов корковой альфа-мощности во время упреждающего внимания к лицам, сценам и инструментам. Однако, учитывая вариабельность между субъектами и присущую им сложность количественной оценки карт различий между субъектами в разных условиях внимания, мы обратились к методу декодирования ЭЭГ, чтобы количественно оценить различия в мощности альфа в условиях, которые качественно описаны выше.
Рис. 3.Карты топографических различий для мощности альфа в эксперименте 1. A , Карты различий для упреждающего внимания к лицам минус сцены. График разности альфа-топографии для условий присутствия минус условия присутствия, усредненных по участникам, для четырех временных окон относительно начала сигнала. Карты топографических различий отображаются только до 1000 мс после начала сигнала, когда могут появиться цели с наименьшей задержкой. Вид на эти разностные карты из-за головы.См. Описание в тексте. B , Карты различий для упреждающего внимания к лицам без инструментов. График разности альфа-топографии для условий посещаемости минус условия посещаемости, усредненные по участникам. C , Карты различий для упреждающего внимания к инструментам без сцен. График разности альфа-топографии для условий посещаемости минус условия присутствия, усредненные по участникам.
Результаты декодирования SVM
Результаты декодирования SVM (рис.4) выявил статистически значимую точность декодирования в двух кластерах временных точек в диапазоне 500–800 мс после спасения и перед целью (рис. 4, бирюзовые точки). Точность декодирования в диапазоне от -100 до +200 мс в начале сигнала не достигла порога статистической значимости.
Рисунок 4.Точность декодирования альфа-диапазона в эксперименте 1. Точность декодирования активности альфа-диапазона в течение эпохи для разных участников. Горизонтальная красная линия представляет собой случайную точность декодирования.Сплошная изменяющаяся во времени линия представляет собой среднюю точность декодирования по каждому объекту в каждый момент времени, а заштрихованная область вокруг этой линии — это SEM. Серая заливка обозначает период предварительного ожидания, а сегмент с оранжевой заливкой представляет период ожидания между началом сигнала (0 мс) и самым ранним наступлением цели (1000 мс). Бирюзовые точки обозначают моменты времени, которые принадлежат статистически значимым кластерам точности декодирования, как определено оценкой Монте-Карло.
Результаты декодирования SVM осцилляторной активности ЭЭГ в тета-, бета- и гамма-диапазонах не выявили статистически значимого декодирования в период ожидания (рис.5).
Рисунок 5.Декодирование для разных частотных диапазонов ЭЭГ в эксперименте 1. A , Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных альфа-диапазона, были применены к тета-диапазону (4– 7 Гц). B , Тот же конвейер декодирования был применен к бета-диапазону (16–31 Гц), что не выявило статистически значимых кластеров с высокой точностью декодирования в подготовительный период. C , Тот же конвейер декодирования также применялся к гамма-диапазону (32–40 Гц) и, аналогичным образом, не выявил статистически значимых кластеров с высокой точностью декодирования в подготовительный период.
Эксперимент 2
Мы наблюдали статистически значимый кластер моментов времени с исключительной точностью декодирования только в окне представления сигнала. Никаких дальнейших кластеров декодирования со значительно большей вероятностью не происходило где-либо от 200 до 1000 мс (рис. 6).
Рисунок 6.Точность декодирования альфа-диапазона для эксперимента 2. Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных из эксперимента 1, были применены к альфа-диапазону ЭЭГ из эксперимента 2, выявив кластер статистически важные моменты времени, близкие к началу сигнала, но не позднее подготовительного периода.
Результаты этого контрольного эксперимента опровергают возможность того, что декодирование позднего периода альфа-диапазона, которое мы наблюдали в нашем первоначальном эксперименте, было просто результатом дифференциальных восходящих сенсорных процессов в трех условиях сигнала. Поскольку парадигма эксперимента 2 была идентична парадигме эксперимента 1 во всех отношениях, кроме достоверности реплики, и поскольку мы использовали тот же конвейер декодирования SVM для данных ЭЭГ в альфа-диапазоне из эксперимента 2, как и в эксперименте 1, мы могли напрямую оценить, была ли модель результатов декодирования, полученных нами в первоначальном эксперименте, связана с восходящими сенсорными процессами.
Мы собрали данные от большего числа участников для эксперимента 2, чем для нашего первоначального эксперимента, чтобы у нас было больше возможностей для оценки величины и временной степени декодирования, которое могло быть достигнуто исключительно на основе вызванной стимулом активности. Наши результаты подтверждают идею о том, что сверх-случайное декодирование с большой задержкой в эксперименте 1 не связано с чисто сенсорной активностью, обусловленной различиями физических стимулов, потому что мы обнаружили, что в эксперименте 2 статистически значимое сверх-случайное декодирование происходило только в кластере времени. указывает на короткую задержку после спасения (<200 мс после начала сигнала; рис.6).
Эксперимент 3
Поведенческие результаты
В задаче отличия размытых изображений от сфокусированных изображений (рис.7) мы наблюдали различия в RT между действительными и недействительными испытаниями для всех категорий объектов, так что испытания с достоверными указаниями вызывали более быстрые ответы, чем неправильно назначенные испытания (рис. 8). Подгоняя обобщенную линейную смешанную модель с гамма-распределением к данным RT, мы обнаружили значительный эффект достоверности ( p <0,001).
Рис. 7.Пример изображения цели в задаче на внимание для эксперимента 3.В этом наборе примеров лицо — это категория целевого объекта, которую нужно идентифицировать как находящуюся в фокусе или размытую, а наложенные изображения инструмента или сцены являются изображениями-отвлекающими элементами. Для каждого стимульного изображения и цель, и отвлекающий фактор могут быть размытыми или в фокусе независимо друг от друга.
Рисунок 8.Поведенческие меры внимания в эксперименте 3. A , Ящичковые диаграммы данных времени реакции для недействительных и достоверных испытаний для 12 субъектов, усредненные по условиям внимания (объекта).Толстые горизонтальные линии внутри прямоугольников представляют собой медианные значения. Первый и третий квартили показаны как нижний и верхний края прямоугольника. Вертикальные линии проходят до самых крайних точек данных, за исключением выбросов. Точки над графиками представляют выбросы, определяемые как любое значение, превышающее третий квартиль плюс 1,5 межквартильного размаха. Субъекты в целом были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимыми). B , Время реакции для действительных и недействительных испытаний отдельно для каждого состояния внимания.Субъекты были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимые) для каждой категории объектов.
Результаты декодирования SVM
Используя тот же анализ ЭЭГ и конвейер декодирования SVM, что и для эксперимента 1, мы обнаружили статистически значимые кластеры временных точек, демонстрирующих точность декодирования выше шансов (рис. 9). Как и в эксперименте 1, эти статистически значимые кластеры наблюдались во второй половине подготовительного периода,> 500 мс после начала сигнала.Примечательно, что в окне представления сигнала 0–200 мс, по-видимому, также имеется группа моментов времени с высокой вероятностью, в тот же период, когда мы наблюдали статистически значимое декодирование в эксперименте 2, которое было связано с сенсорной активностью, вызванной сигналом. Однако в результатах эксперимента 3, как и в эксперименте 1, декодирование в этот период времени предъявления сигнала (задержка <200 мс) не достигло уровня статистической значимости (тогда как при большем количестве участников в эксперименте 2 это могло быть выявлено. ).
Рисунок 9.Точность декодирования альфа-диапазона для эксперимента 3. Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных из эксперимента 1, были применены к альфа-диапазону ЭЭГ из эксперимента 3, выявив кластер статистически знаменательные моменты времени во второй половине подготовительного периода.
Поведенческие результаты эксперимента 3 предполагают, что участники привлекали объектно-ориентированное внимание в течение подготовительного периода. Участники быстрее распознавали изображения объектов как размытые или сфокусированные, когда их категория была указана.По аналогии с парадигмами пространственного внимания с указаниями, в испытаниях с неверно указанными объектами участники обращались к одной категории объектов в течение подготовительного периода, но затем при предъявлении стимула переориентировали свое внимание, чтобы иметь возможность различать, было ли изображение из категории объектов без привязки размытым или размытым. фокус.
Поскольку поведенческий эффект между действительными и недействительными испытаниями соответствует таковому в нашем первоначальном эксперименте, мы уверены, что экспериментальный план в эксперименте 3 порождал ту же форму объектно-ориентированного внимания сверху вниз, как это было зафиксировано в эксперименте 1.Следовательно, при наблюдении статистически значимого сверхшансного декодирования в том же общем окне времени после появления сигнала для экспериментов 1 и 3 мы интерпретируем этот результат как доказательство того, что внимание, основанное на объекте, а не различия в постановке задачи или подготовке двигательной реакции, является движущей силой. результат декодирования с большей задержкой до наступления целей.
Обсуждение
Объектное внимание — фундаментальный компонент естественного зрения. Люди перемещаются по миру в основном на основе взаимодействий с объектами, которые изобилуют в типичных средах (O’Craven et al., 1999; Scholl, 2001). Примат объектов означает, что адаптивное взаимодействие с миром требует представлений объектов высокого уровня, которые отличаются от визуальных характеристик низкого уровня в той же области пространства. Следовательно, воздействие внимания непосредственно на репрезентации объектов является критическим аспектом восприятия (Woodman et al., 2009). Было показано, что внимание действует на репрезентации объектов (Типпер и Берманн, 1996; Берманн и др., 1998), поэтому выявление нейронных механизмов, с помощью которых внимание влияет на репрезентации объектов, является ключевой задачей когнитивной нейробиологии.
Физиологические исследования показывают, что повышение эффективности внимания коррелирует с изменениями нейронной активности в системах восприятия. Корковые структуры, кодирующие сопровождаемую информацию, показывают повышенную амплитуду сигнала, синхронность и / или функциональную связность (Moore and Zirnsak, 2017). Как нервная система механистически контролирует эту корковую возбудимость и эффективность обработки, остается не совсем понятным, но большинство моделей предполагают, что нисходящие управляющие сигналы от сетей более высокого порядка в лобной и теменной коре изменяют обработку в сенсорных / перцептивных областях коры, кодирующих посещаемую и необслуживаемую информацию ( Петерсен и Познер, 2012).Одной из гипотез нейронной сигнатуры нисходящего контроля на уровне сенсорной / перцептивной коры является фокусная альфа-сила (Jensen and Mazaheri, 2010). Изменения в мощности альфа происходят во время пространственного внимания (Worden et al., 2000) и особого внимания (Snyder and Foxe, 2010). Здесь мы исследовали механизмы на основе альфа-канала, обеспечивающие избирательное внимание к объектам, направляя внимание на различные объекты и измеряя изменения в записанной на коже головы альфа-мощности ЭЭГ. Мы объединили поведение с топографическим картированием и декодированием ЭЭГ, чтобы проверить гипотезу о том, что внимание к объекту включает в себя селективные модуляции мощности альфа-излучения в объектно-специфической коре головного мозга.
Мы выбрали лица, сцены и инструменты в качестве целей внимания, потому что было показано, что эти объекты активируют ограниченные области в зрительной коре головного мозга. Веретенообразная область лица (FFA) избирательно реагирует на изображения вертикальных лиц (Allison et al., 1994; Kanwisher and Yovel, 2006): лица могут считаться объектами, потому что, например, данные пациентов с прозопагнозией предполагают, что аналогичные механизмы лежат в основе распознавания лиц и объектов (Gauthier et al., 1999).Площадь парагиппокампа (PPA) реагирует на сцены (Epstein et al., 1999) и, в частности, на категорию сцены (Henriksson et al., 2019). Области, чувствительные к инструментам, были идентифицированы в вентральном и дорсальном зрительных путях (Kersey et al., 2016). В соответствии с предсказанием, что объектно-ориентированное внимание модулирует альфа-канал в визуальных областях, специализированных для обработки категории наблюдаемых объектов, внимание к лицам должно выборочно снижать активность альфа-диапазона в визуальных областях с отбором по лицам, таких как FFA, внимание к сценам должно уменьшать альфа-диапазон активность в отобранных по месту областях, таких как PPA, и внимание к инструментам должно снизить активность альфа-диапазона по сравнению с селективными по инструментам областями вентральных и дорсальных зрительных путей.ЭЭГ не является сильным методом локализации нейронных источников активности мозга, но, учитывая, что области FFA, PPA и постулируемые специализированные области инструментов расположены в разных областях коры головного мозга, закономерности альфа-модуляции с вниманием в этих областях можно было бы ожидать. для получения дифференциальных альфа-паттернов ЭЭГ на коже черепа. Учитывая, что можно ожидать, что такие паттерны будут лишь незначительно отличаться и трудно предсказать, одним из способов оценки различных паттернов альфа для внимания к разным объектам является включение машинного обучения для декодирования альфа-паттернов ЭЭГ кожи головы.Таких различий следует ожидать только в том случае, если фокусная модуляция альфа также участвует в избирательном внимании объекта.
Наши результаты по времени реакции показали, что участники, которые обращали внимание на объектно-ориентированное внимание на категории объектов, на которые указывает указание, быстрее идентифицировали объекты с указанием. Теоретически, когда участники должны предвидеть конкретную категорию объектов, они будут искажать нейронную активность в областях коры, специализированных для этого типа объекта, и, возможно, также искажать активность в областях коры, обрабатывающих все визуальные особенности нижнего уровня, связанные с этим объектом (Коэн и Тонг, 2015).Когда цель появляется, ее визуальные свойства интегрируются, облегчая требуемое восприятие различения. Когда появляется объект из непредвиденной (необработанной) категории, активность в областях, отобранных для объекта, и связанных областях визуальных характеристик для объектов без привязки будет относительно подавлена, что задерживает интеграцию и семантический анализ несвязанных целевых изображений и замедляет время реакции.
Топографические карты альфа-различий менялись в зависимости от категории объекта, на котором присутствовали участники.Различная альфа-топография соответствовала паттернам ЭЭГ кожи головы, которые можно было бы ожидать, если бы альфа-модуляции происходили в разных основных корковых генераторах (корковых пятнах или областях) для трех категорий объектов. Множество доказательств лежащих в основе нейроанатомических субстратов лица, сцены и обработки инструментов из исследований изображений позволяет делать некоторые прогнозы относительно наших данных в отношении предполагаемой природы фокальной корковой активности, вносящей вклад в наши топографические и декодирующие результаты.FFA с акцентом на правое полушарие (Kanwisher et al., 1997) и одинаково двусторонне распределенный PPA (Epstein and Kanwisher, 1998), в принципе, предсказывают дифференциальное альфа-распределение скальпа и, возможно, более низкую альфа-мощность в целом по правой затылочной кости. при посещении лиц. Наша альфа-топография посещаемости минус посещаемость сцены в целом соответствовала этому прогнозу (рис.3 A ), и эта картина отличалась от графика на графике разницы посещаемости минус посещаемость-инструмент (рис.3 В ). Однако мы надеемся прояснить, что мы не предполагаем, что мы можем локализовать лежащие в основе корковые генераторы регистрируемой активности кожи головы, используя методы, которые мы использовали здесь; поэтому мы обратились к декодированию.
Наш анализ декодирования убедительно подтверждает утверждение о том, что внимание модулирует альфа-топографии в зависимости от категории объекта и согласуется с временными курсами различий в альфа-образцах, наблюдаемых на графиках топографических различий скальпа.В нашем анализе декодирования статистически значимая точность декодирования с высокой вероятностью обеспечивает прямое свидетельство того, что альфа-топография содержит информацию о выбранной категории объекта, и, следовательно, что внимание, основанное на нисходящем объекте, модулирует альфа-топографию в соответствии с категорией объекта с указанием (сопровождаемым) . Мы наблюдали, что статистически значимое декодирование происходило в диапазоне 500-800 мс после спасения / предварительной цели, что указывает на то, что паттерны альфа-топографии на коже черепа надежно модулировались нашим манипулированием вниманием в этом временном диапазоне (рис.4). Важно отметить, что диапазон 500–800 мс соответствует периодам на графиках альфа-топографических разностей, где изображения стабилизировались.
Чтобы проверить, были ли наши результаты декодирования специфичными для альфа-диапазона, мы выполнили ту же процедуру декодирования SVM для мощности в тета-, бета- и гамма-диапазонах и не обнаружили значительного превосходного декодирования в период ожидания для этих полосы частот (рис. 5). Этот результат согласуется с гипотезой о том, что осцилляторная нейронная активность в альфа-диапазоне механически участвует в упреждающем внимании, тогда как активность в других частотных диапазонах ЭЭГ не модулируется в соответствующих целевых визуальных областях ЭЭГ человека.
В двух последующих экспериментах мы непосредственно оценили две альтернативные интерпретации наших результатов декодирования из эксперимента 1. Во-первых, различия в альфа-топографии скальпа после спасения могут отражать чисто сенсорную обработку, связанную с каждым сигналом (например, треугольник против круга). Это должно быть применимо только к декодированию с повышенной вероятностью (хотя и незначительным по нашим тестам), наблюдаемому в ранний период после спасения (∼0–200 мс) на рисунке 4, а не к декодированию с более длительной задержкой.Действительно, мы проверили это в эксперименте 2, в котором участники выполняли ту же задачу и видели те же сигналы и цели, что и в эксперименте 1, но форма сигнала не предсказывала предстоящую категорию объекта. Мы наблюдали статистически значимое декодирование в период после спасения / предварительной цели от 0 до 200 мс, связанное с физическими функциями реплики (Bae and Luck, 2018), но не было значимого декодирования позже в интервале от реплики к цели.
Второе альтернативное объяснение наших результатов декодирования из эксперимента 1 состоит в том, что они были вызваны различиями в наборах задач в зависимости от условий объекта.Задача для лиц, например, заключалась в различении пола, в то время как для сцен — различать городские сцены и природные сцены, оставляя открытой возможность того, что наше декодирование в конце периода после спасения отражало различия в поставленных задачах (Hubbard et al., 2019 ), а не контроль внимания над выбором объекта, как мы предлагаем. Мы можем отклонить эту альтернативу на основе результатов эксперимента 3, в котором реплики предсказывали соответствующий целевой объект, но задача распознавания была одинаковой для всех категорий объектов: различать, был ли объект, на который была подана подсказка, был в фокусе или размыт.Таким образом, мы смогли воспроизвести подготовительные эффекты внимания, связанные с альфа-альфа с большей задержкой, о которых сообщалось в эксперименте 1, при одновременном контроле факторов набора задач.
Наши результаты показывают, что альфа-модуляция ЭЭГ связана с избирательным вниманием на основе объектов, расширяя предыдущие выводы о том, что альфа-модуляция связана с вниманием к пространственным местоположениям и визуальным особенностям низкого уровня. Используя подход к декодированию SVM, мы выявили различия в топографических паттернах мощности альфа-канала во время выборочного внимания к разным категориям объектов.Кроме того, мы связали временной диапазон, в течение которого было достигнуто статистически значимое декодирование, с топографическими картами с усилением альфа-канала и наблюдали, что альфа-модуляция согласуется с временным ходом подготовительного внимания, наблюдаемым в предыдущих исследованиях. В целом, эти результаты подтверждают модель, согласно которой нейронная активность в альфа-диапазоне функционирует как модулятор внимания сенсорной обработки как для зрительных функций низкого уровня, так и для нейронных репрезентаций высокого порядка, таких как репрезентации объектов.
Footnotes
Эта работа была поддержана грантом Mh217991 для G.R.M. и M.D. S.N. поддерживался T32EY015387. Мы благодарим Майкла Дж. Тарра, Центр нейронных основ познания и Департамент психологии Университета Карнеги-Меллона (http://www.tarrlab.org/) за изображения стимулов на лице при финансовой поддержке премии Национального научного фонда 0339122. Мы также благодарим Стивена Дж. Лака и Ги-Йеул Бэ за советы по анализу с использованием методов декодирования, а также Атиша Кумара и Тамима Хассана за помощь в сборе данных.
Авторы заявляют об отсутствии конкурирующих финансовых интересов.
- Переписку следует направлять Джорджу Р. Мангуну по адресу grmangun {at} ucdavis.edu
Надписывание длинного хвоста с помощью древовидной структуры декодирования сложных категорий | Труды Ассоциации компьютерной лингвистики
Одной из неотъемлемых проблем задачи супертэгов является разреженность выходного пространства. Однако это недостаточно отражено в стандартных наборах оценок, как показано на Рисунке 1b.Чтобы проверить, насколько хорошо модели действительно обобщаются для длинного хвоста, мы оцениваем их на альтернативно выборочных обучающих и оценочных разделениях данных WSJ (таблица 6), а также в областях, расходящихся с обучающим набором WSJ (таблица 7). Эти эксперименты в значительной степени подтверждают наши выводы из стандартного набора оценок Rebank, в то время как изменение в распределении категорий оказывает несколько важных эффектов на нашу способность оценивать обобщение модели: во-первых, производительность OOV намного выше для перераспределенных данных (таблица 6), чем для стандартных Тестовые разбиения в таблицах 3, 4 и 7 подчеркивают возможности обобщения всех конструктивных моделей и, в свою очередь, предполагают, что категории OOV в разделе 23 WSJ и PMB действительно сложны, шумны или иным образом несовместимы с данными обучения.Во-вторых, доля оценочных токенов категорий менее 10 раз в обучении составляет 1,6% в PMB и 3,8% в наших перераспределенных оценочных данных Rebank, по сравнению с только ≈0,2% в стандартных тестовых наборах CCGbank и Rebank. Это 7–16-кратное увеличение относительного размера делает хвост гораздо более значимым для общей производительности. И действительно, мы наблюдаем немного меньший разрыв в общей точности между наиболее эффективными неконструктивными и наиболее эффективными конструктивными системами в Таблице 7 (0,08 на Wiki, 0.11 на PMB) по сравнению с 0,13 в таблицах 3 и 4, а в таблице 6 AddrMLP даже явно превосходит неконструктивные модели. В-третьих, эффективность по редким и невидимым категориям теперь может быть измерена гораздо более надежно благодаря большему количеству абсолютных редких и невидимых категорий. Мы предоставляем подробный анализ этого подмножества тегов в п. 6.2.
Как для внутренних, так и для внешних данных разрыв в производительности между неконструктивными MLP и AddrMLP в наиболее часто встречающихся категориях минимален и фактически находится в пределах стандартного отклонения.Учитывая тенденцию, которую мы наблюдаем от Таблиц 3 и 4 до Таблиц 6 и 7, возможность обобщения до длинного хвоста вполне может перевесить любое незначительное улучшение наиболее часто встречающихся категорий при применении к еще более разнообразным данным на других языках и на разных языках.